Cloudflare推出AI爬虫分类管控工具,站长可对三类爬虫执行差异化策略
7月1日,Cloudflare正式上线一套AI流量管理工具,网站所有者可以针对不同类型的AI爬虫设置精细化的访问规则。
过去,防御恶意爬虫的手段往往只能全量屏蔽外部访问,容易误伤搜索引擎,拖累网站排名。这次更新的核心改变,是把原本笼统的“AI流量”拆成了三类:搜索爬虫、智能体爬虫和训练爬虫。站长能按业务需求,对这三类爬虫分别选择放行或拦截。
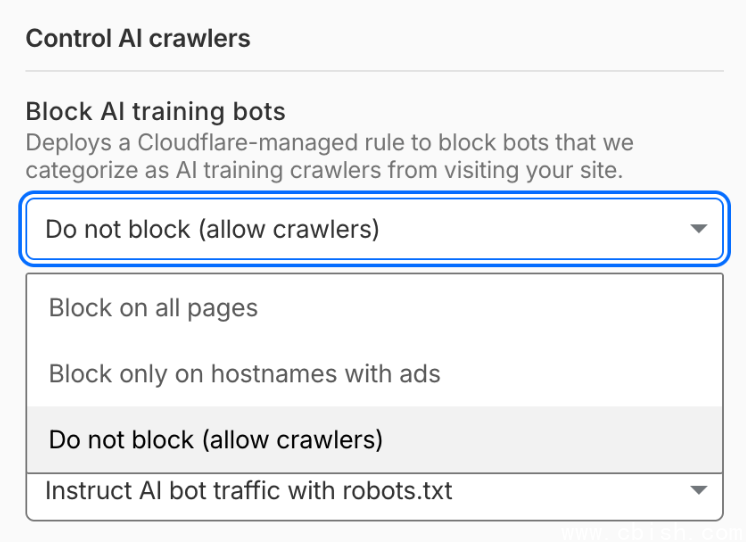
对依赖广告收入的站点来说,这相当实用。在新的管理框架下,网站可以保护核心广告页面,阻止AI爬虫高频抓取产生的无效流量,避免广告投放的精准度和收益受损。也就是说,来自主流搜索引擎的正常流量不会受影响,而那些专门“窃取”内容用于模型训练的爬虫则可以被挡在门外。
有分析指出,这一动作标志着AI与内容生态的博弈,已经从简单的屏蔽对抗转向更具策略性的精细化治理。在算力和数据版权博弈日趋激烈的背景下,这套工具相当于给站长提供了一把保护数据资产和流量价值的“手术刀”,在AI发展的技术需求与内容创作者利益之间划出了一条可操作的界线。