为什么你的AI助手越用越“笨”?一场颠覆性的技术革命正在发生
你有没有遇到过这种情况:让AI读完一本1000页的报告,然后问它第三章第5页的某个细节——它要么答非所问,要么干脆说“我记不清了”?这不是你AI太差,而是所有大语言模型都面临的“记忆天花板”。
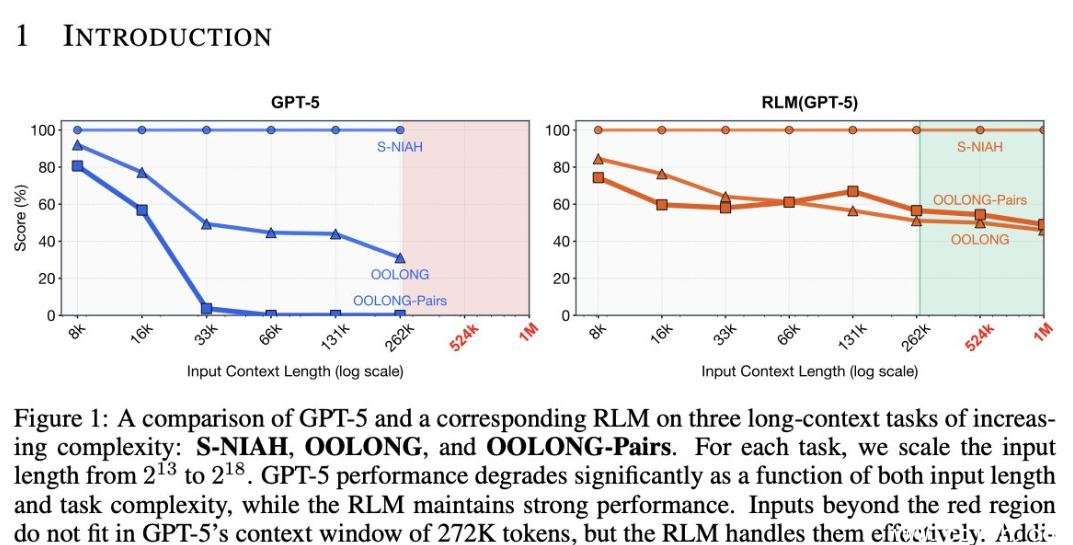
当上下文长度超过几万token,模型的准确率会断崖式下跌。更糟的是,每多塞一个词,算力成本就涨一截。你花的钱,一半在“记住废话”,一半在“反复推演已知信息”。这就像请一位博士生读完图书馆全部藏书,只为回答一个选择题——效率低、烧钱、还容易出错。
但就在2025年10月,一位名叫Alex Zhang(张亚历)的研究者,在一篇低调却震撼的博客中,提出了一种彻底改变游戏规则的方案:递归语言模型(Recursive Language Model, RLM)。它不靠“硬记”,而是教AI“会管理”。
AI有了自己的“办公室”:不是更强,而是更聪明地工作
想象一下,你请了一个助理,他不靠死记硬背,而是有一个带电脑的独立办公室。他能:
- 把PDF、视频、表格直接拖进Python环境,按需调用
- 写几行代码自动提取关键段落,过滤噪音
- 叫来3个“分身”同时查资料、算数据、核对引用
- 把中间结果存进变量,反复检查、修正,直到完美
- 最后只给你一个干净的答案,中间所有“思考痕迹”自动清理
这就是RLM的精髓:它不再是一个“单线程记忆机器”,而是一个能调度工具、管理任务、自我优化的“智能团队长”。
Prime Intellect团队的实验数据,彻底颠覆了传统认知:
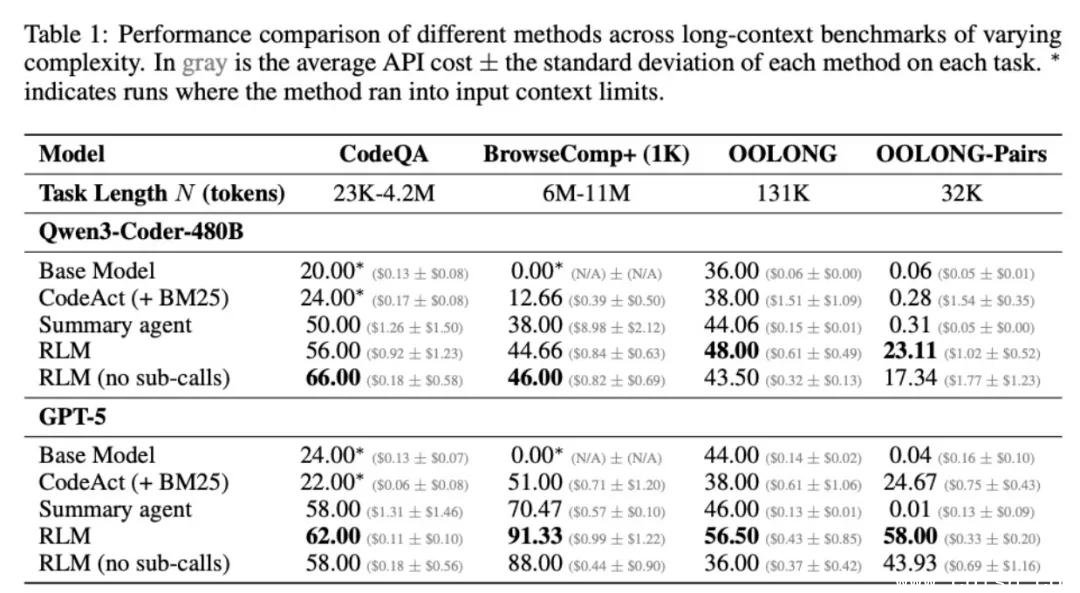
- DeepDive(复杂知识图谱推理):RLM准确率提升37%,主模型上下文占用减少62%——大部分计算被“外包”给子模型,成本直降。
- Oolong(长文本信息聚合):在处理超过20万token的论文集时,RLM仍能精准定位关键结论,普通模型早已“信息过载”。
- verbatim-copy(逐字复制测试):普通模型平均错误率18%,RLM通过“写入变量→打印检查→修正→再验证”的循环,错误率压到2.1%。这相当于AI自己当了编辑和校对员。
唯一“翻车”的是math-python任务——但这不是RLM不行,而是模型还没学会“怎么用RLM”。就像你给一个高中生一台Python电脑,他不会写代码,不代表电脑没用。训练数据和提示工程一跟上,性能立刻起飞。
这不是升级,是范式转移:AI正在从“记忆体”变成“执行者”
当前主流AI智能体,像一个永远在背书的考生。你问得越多,它越累,越容易出错,成本越高。
而RLM,是让AI学会“管理注意力”和“分配任务”。它知道:
- “这段内容不重要,不用记”
- “这个数据要查数据库,交给子模型”
- “答案写错了?重算一遍”
- “用户要的是结论,不是我思考的5000行草稿”
这意味着什么?
- 你可以让AI连续工作7天,读完100份财报、10部纪录片、5000条用户反馈,最终输出一份综合战略报告——而不会因为“上下文腐烂”中途崩溃。
- 企业级AI客服,能调取你过去半年的所有聊天记录、订单、工单,精准还原问题脉络,而不是每次重启都“失忆”。
- 科研助理能自动追踪你三个月前引用的那篇论文,找到它的最新修正版,甚至提醒你:该作者今年3月发了反驳文章。
未来已来:RLM不是终点,而是起点
目前RLM还处于实验室阶段,但路线图已经清晰:
- 深度递归:子模型可以再调用孙模型,形成“AI团队金字塔”,解决超复杂任务。
- 多模态原生支持:直接处理图像、音频、代码仓库,不再需要“转文本”这个低效中间步骤。
- 自主学习记忆策略:通过强化学习,AI自己学会“什么该记、什么该丢”,像人类一样形成“长期记忆”。
更关键的是,RLM让AI从“黑箱回答器”变成“可解释的决策者”。你不再只是得到一个答案,还能看到它:为什么选这个数据源?为什么排除那条信息?哪个子模型负责哪部分?——这正是企业、科研、法律等高风险领域最需要的透明度。
Prime Intellect团队在论文末尾写道:“我们不再追求更大的上下文窗口,而是追求更聪明的上下文管理。”
如果你还在用“喂更多token”来解决AI记不住的问题——你已经落后了。真正的下一代AI,不是更大,而是更懂“分工作业”。
下次当你问AI一个复杂问题,别只期待它“答对”,更要期待它说:“我先查一下你的历史记录,叫个助手核对下数据,五分钟给你完整报告。”——那才是真正的智能。