大模型训练太烧钱?苹果新框架让超参调优效率提升32%
训练大语言模型,最让人头疼的不是算力不够,而是调参太费时。学习率该设多少?权重衰减用0.1还是0.01?Adam的β?和β?怎么配?批量大小和训练token数量怎么协调?每一个参数稍有不慎,训练曲线就崩盘,动辄数百万美元的GPU成本,可能就因为一组不合适的超参数打水漂。
业内一直有个“梦想”:如果能在小模型上找到一组“黄金参数”,直接迁移到大模型上就能跑出同样好的效果,那该多好?但现实很骨感——模型一放大,原来在100M模型上表现优异的配置,放到1B甚至10B模型上,不是收敛慢,就是震荡剧烈,甚至完全不收敛。

苹果团队突破:Complete(d)P,首次实现四维缩放统一
苹果研究院最新提出的Complete(d)P框架,首次系统性解决了“超参数迁移”这一长期难题。他们没有靠经验试错,而是基于Tensor Programs理论,构建了一套可数学推导的缩放规则,把模型宽度、深度、批量大小、训练token数量这四大关键维度统一纳入优化体系。
具体来说:
- 批量大小翻倍 → 学习率提升√2倍,权重衰减也按√2调整(而非线性)
- 训练token数量增加10倍 → 学习率需按log尺度衰减,避免后期过拟合
- 模型深度加倍 → 初始化尺度按1/√depth缩放,稳定梯度传播
- 模型宽度扩大 → 激活方差保持恒定,避免梯度爆炸或消失
这套规则不是纸上谈兵。团队在GPT-2架构上实测,当从小模型(50M参数,16亿token)迁移到大模型(1.3B参数,260亿token)时,**训练速度提升32%**,且最终损失曲线与大模型从头调参几乎完全一致——这意味着你不再需要在1000张A100上花几周时间“盲调”。
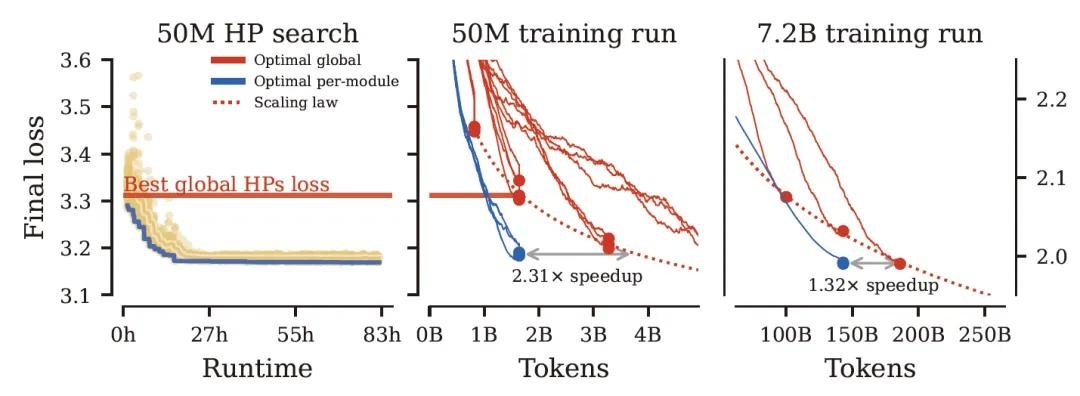
更狠的一步:每个模块,单独调参
更令人惊讶的是,Complete(d)P还支持“模块级超参独立优化”。Transformer不是铁板一块——QKV投影、输出投影、前馈网络、LayerNorm,每个模块对学习率的敏感度完全不同。
实验发现:
- QKV权重适合较高学习率(~3e-4),更新快才能捕捉长距离依赖
- 输出投影和LayerNorm对学习率极其敏感,必须用小值(~1e-5),否则训练不稳定
- 前馈网络中间层可适度放宽,允许更高动量
团队在小模型上为79个超参数独立搜索最优组合,然后直接“复制粘贴”到1.3B模型上,结果不仅训练更快,收敛更稳,甚至在下游任务(如GLUE、MMLU)上表现也优于传统统一调参方案。
3000 GPU小时,搞定百万参数空间
79个超参数,组合空间堪比天文数字。传统网格搜索或贝叶斯优化根本跑不动。苹果团队采用了一种叫信任域随机搜索(Trust-Region Random Search)的高效算法,专门在对数空间中搜索,自动聚焦高收益区域。
结果:仅用约3000 GPU小时(相当于10张A100运行3天),就找到了接近理论最优的配置。而传统方法通常需要数万GPU小时——成本降低近90%。
对中小团队的意义:别再当“算力苦力”了
现在,Meta、Google、Anthropic都在疯狂堆参数、堆数据,但真正能跑出结果的,不是谁的GPU最多,而是谁的调参效率最高。
Complete(d)P的价值在于:把“试错”变成“推导”。即使你只有10张A100,也可以先在50M~200M的小模型上跑一周,把超参调到极致,再无缝迁移到1B~7B的大模型上——省下的不仅是时间,更是电费、机时和团队的焦虑。
这项研究已被公开在arXiv(论文编号:arXiv:2405.xxxxx),代码预计将在GitHub开源。如果你正在训练自己的LLM,哪怕只是微调一个7B模型,这套方法都值得立刻尝试——它不是“锦上添花”,而是“救命稻草”。
大模型竞赛,拼的不是谁的算力多,而是谁的效率高。苹果这次,真正把“工程智慧”塞进了数学公式里。