AI推理新纪元:英伟达Blackwell GB200 NVL72如何彻底改写性能格局
国际权威机构Signal65最新发布的AI推理芯片性能报告,掀起了一场行业地震。英伟达最新推出的Blackwell GB200 NVL72系统,在MoE(混合专家)模型推理场景中,不仅将前代H200远远甩开,更以高达28倍的单GPU性能优势,将AMD MI355X彻底压制——这已不是“小幅领先”,而是结构性碾压。
很多人仍以为AI推理比的是算力密度、FP8吞吐或显存带宽,但现实早已转向一个更隐蔽、更致命的战场:**系统级通信效率**。
真正的天花板,不是算力,是网络
MoE架构是当前大模型的主流方向——它把一个庞大的模型拆成数百个“专家子网络”,每个输入token只激活其中少数几个。听起来很高效,但一旦这些专家分布在不同GPU上,问题就来了:
- 每个token需要在多个GPU间“跳转”——触发密集的all-to-all通信;
- KV缓存(键值缓存)必须跨节点同步,否则无法维持上下文连贯性;
- 通信延迟一旦成为瓶颈,哪怕你有1000个GPU,也只会集体“等饭吃”。
这就是为什么许多厂商的8-GPU或16-GPU系统跑着跑着就“撞墙”——不是芯片不够强,而是**互联架构撑不住**。
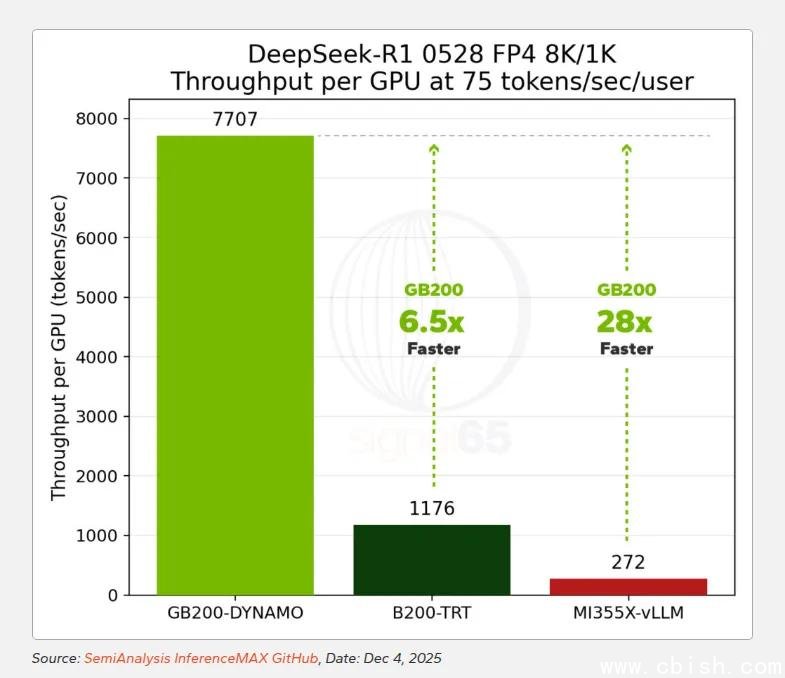
数据说话:从1.8倍到28倍,差距是如何被拉大的
在Llama 3.3 70B模型、8K输入+1K输出的标准测试中,GB200与MI355X的差距仅为1.8倍——这让人误以为AMD还有机会。
但当交互速率提升到**110 tokens/sec/user**(接近真实对话型AI服务的峰值负载),情况彻底反转:GB200的吞吐量直接飙到MI355X的**6倍以上**。
更震撼的是DeepSeek-R1的测试——一个总参数671B、活跃参数37B的超大规模MoE模型:
- AMD的8-GPU集群在跨节点部署后,性能增长曲线迅速饱和,**根本无法线性扩展**;
- 而72颗GPU组成的GB200 NVL72系统,却能一路稳稳线性扩展,直到满载。
在75 tokens/sec/user的高并发场景下,**单颗GB200 GPU的推理吞吐量,是MI355X的28倍**。
即便GB200的单GPU小时成本比MI355X高出1.86倍,其**性能价格比依然领先15倍**——也就是说,每生成一个token的成本,仅为对手的**十五分之一**。
高并发才是AI服务的生死线
以下是不同交互速率下的真实性能对比(基于Signal65实测):
- 25 tokens/sec/user:GB200单GPU性能为H200的10倍,MI325X的16倍
- 60 tokens/sec/user:对比H200提升24倍,对比MI355X提升11.5倍
- 100 tokens/sec/user:性能是MI355X的近3倍(8月时仅为1.4倍)
- 250 tokens/sec/user:领先幅度扩大至6.6倍——这已逼近当前主流AI应用的实际需求峰值
注意:250 tokens/sec/user不是实验室数字。它对应的是一个中型AI助手服务,同时服务5000名用户、每人每秒请求1次的场景——这正是字节、腾讯、OpenAI、阿里通义等一线厂商正在面临的现实压力。
价格便宜≠成本更低:AI推理是系统工程
AMD MI355X确实便宜——单卡价格约为GB200的一半。但问题在于:
- 你买8张MI355X,可能只能跑出1张GB200的性能;
- 你需要额外部署更多网络交换机、更复杂的调度系统、更耗电的冷却方案;
- 运维复杂度、故障率、部署周期全部飙升。
GB200 NVL72的真正护城河,不在芯片本身,而在它的**全栈协同设计**:
- 72颗GPU通过NVLink 5.0构建无阻塞互联fabric,通信延迟低至纳秒级;
- NVIDIA NVSwitch实现GPU间全连接,避免传统PCIe拓扑的“交通堵塞”;
- TensorRT-LLM + Triton Inference Server深度优化MoE调度,自动分配专家、预加载缓存、动态负载均衡;
- Grace CPU + Blackwell GPU异构融合,让控制流与计算流无缝协同,减少CPU瓶颈。
这些不是“功能”,而是**系统级的工程壁垒**。AMD目前仍依赖传统PCIe + InfiniBand架构,软件生态也尚未实现同等粒度的MoE调度能力——这意味着,即便他们明年推出MI360,也很难在系统层面追平。
谁在为这笔账买单?答案正在改变
对于中小型AI创业公司,或许还能靠低价卡“熬”一阵子。但对头部云服务商、大模型平台、智能客服系统、实时AI助手提供商来说——
每多等100毫秒,用户就可能流失;每多花1分钱的推理成本,利润就被压缩一分。
GB200 NVL72虽然单卡贵,但**单位推理成本低到离谱**。在高并发场景下,它能让一个1000台服务器的集群,缩减到仅需60台——省下的机房租金、电费、运维人力、网络带宽,远超硬件差价。
据知情人士透露,某国内头部AI公司已将GB200 NVL72作为2025年新模型上线的**唯一指定硬件平台**,原因只有一句:“我们算过,用别的,用户等不起,我们等不起。”
这场竞赛,早已不是芯片参数的比拼,而是**系统效率、工程能力与商业落地的终极对决**。英伟达,正在用Blackwell重新定义“AI基础设施”的标准。