AI编程助手迎来革命:Meta新系统无需人类数据,靠“自我出题”超越顶尖模型
你有没有想过,未来的AI程序员可能根本不需要看人类写的问题描述、测试用例或代码注释?它不需要“背题库”,而是像一个真正的工程师一样,钻进真实代码库里,自己找茬、自己修bug,边犯错边成长——这不再是科幻,而是Meta FAIR团队刚刚发布的Self-play SWE-RL(简称SSR)系统正在实现的现实。
目前主流的AI编程助手,比如GitHub Copilot、Amazon CodeWhisperer,甚至OpenAI的GPT系列在编程任务中的表现,都高度依赖人类标注的数据:GitHub上的issue、Pull Request、提交日志、测试用例……这些数据就像老师给学生划的重点题,AI学得再好,也始终在人类已知的框架内打转。一旦遇到新场景、新框架、新团队的编码风格,它们就容易“卡壳”。
更关键的是,高质量的人工数据正在枯竭。GitHub上能被有效标注的开源项目有限,企业内部代码又无法公开,训练数据的天花板早已可见。
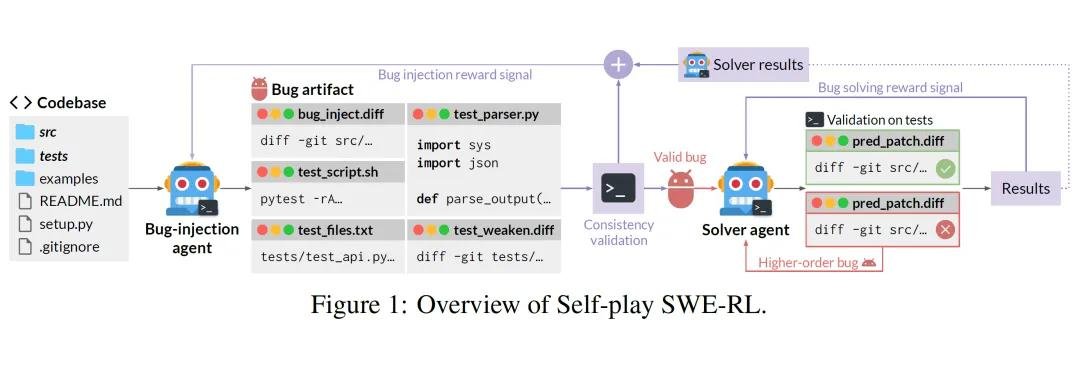
双角色自循环:AI自己当出题人,也当解题人
SSR的突破,来自一个极其聪明的设计——它让同一个AI模型同时扮演两个角色:出题者和解题者。
出题者不靠人类,而是直接接入真实开源仓库(如Linux内核、TensorFlow、React等),随机删除关键函数、回滚历史提交、篡改配置文件,制造出真实、复杂、有语义的bug。这些bug不是“为了难而难”,而是真实开发者曾经犯过的错误,甚至是那些被修复后又被遗忘的“潜伏型缺陷”。
解题者则面对这些“无提示”的代码现场,必须自己读懂上下文、理解模块依赖、分析调用链,才能定位问题并提交修复方案。它没有“题目描述”,没有“预期输出”,它只能靠代码本身推理。
这和过去所谓的“自我对弈”方法(如Absolute Zero)有本质区别。那些系统在模拟环境中玩抽象规则游戏,而SSR直接在真实世界的代码海洋里游泳——每一行代码都带着历史、依赖和工程语义。
错题变考题:AI的“错题本”越攒越厚
SSR最惊艳的,是它的“高阶bug机制”。
当解题者第一次尝试修复某个bug失败,这个失败本身不会被丢弃,而是被系统记录下来,重新打包成一个“新问题”——一个连AI都搞不定的难题,反而成了下一轮训练的黄金素材。
这就像一个学霸在刷题:做错一道题,老师不会让你重做十遍,而是把它放进你的专属错题本,下次考试重点考。SSR就是这么干的。它不断生成“刚好卡住AI”的问题,让模型始终在能力边界上挑战自己。
研究团队发现,存在一个“最优难度区间”:大约20%的解决成功率,是训练效率最高的黄金点。太简单的bug,AI一眼看穿,没进步;太难的,永远解不出,反而挫败模型。只有那些“差一点就能解决”的问题,才是真正的成长催化剂。
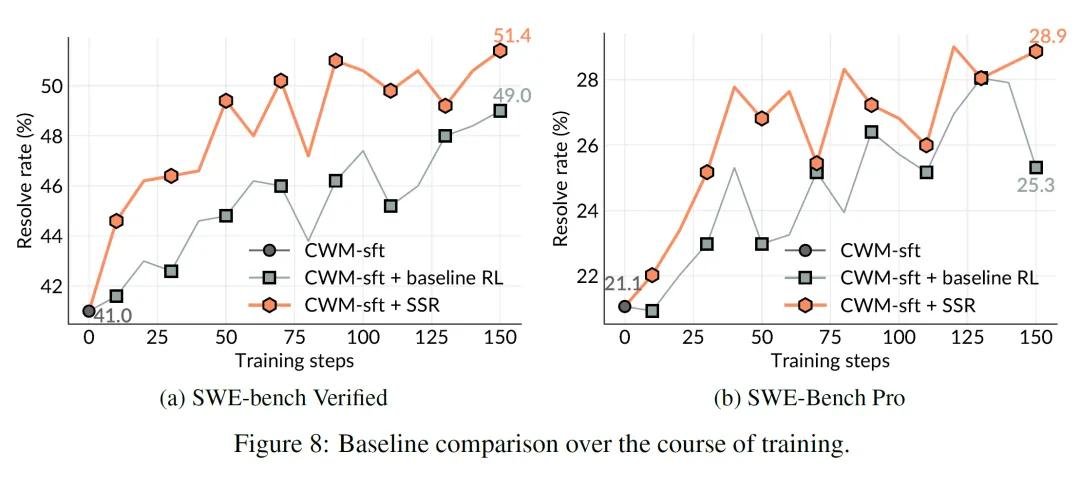
实战碾压:不看人类题,却比人类教的更强
在两个权威基准测试中,SSR的表现令人震惊:
- SWE-bench Verified(500个真实开源项目问题):准确率提升10.4%,超越所有使用人类标注数据的基线模型,包括GPT-4o、Claude 3.5和专门微调的CodeLlama。
- SWE-Bench Pro(731个企业级复杂任务):提升7.8%,在涉及数据库迁移、多模块集成、异步并发等真实工程场景中表现尤为突出。
更惊人的是:SSR在训练和测试过程中,完全没接触过任何人类撰写的issue描述或测试用例。它不知道“修复这个bug”是什么意思,但它能从代码变化中推断出“这里出了问题”。
这意味着,它不是在“回答问题”,而是在“理解系统”。它学会的不是“怎么写代码”,而是“为什么代码会出错”——这是走向真正软件智能的关键一步。
未来已来:AI或将自主构建下一代软件系统
Meta团队在论文中直言:“SSR只是通向超智能软件代理的第一步。”但这第一步,已经动摇了AI编程的底层逻辑。
目前,SSR仍有局限:它还不能自动生成自然语言的用户问题描述,对超大型项目(如Android系统)的长期依赖链处理能力有限,也不支持实时协作式开发。
但它的潜力远不止于“修bug”。研究人员推测,未来这种系统可能:
- 自动理解遗留系统的架构,无需文档即可重构;
- 在开源项目中自主发现安全漏洞并提交补丁;
- 根据用户需求,从零构建完整模块,甚至设计API接口;
- 最终,成为一个能“读懂代码历史”的智能体,像人类工程师一样理解技术演进的脉络。
2025年,GitHub上已经出现AI提交的Pull Request被人类开发者合并的案例。而SSR的出现,意味着我们可能正站在一个转折点上:未来,AI不再是程序员的助手,而是代码世界的“原住民”。
当AI不再需要人类教它“怎么写代码”,它才真正开始理解“为什么代码存在”。