通义千问发布两款革命性TTS新模型:自由设计声音,3秒克隆人声
通义千问团队正式推出 Qwen3-TTS 语音合成家族的两大突破性成员:声音设计模型 Qwen3-TTS-VD-Flash 与声音克隆模型 Qwen3-TTS-VC-Flash。两款模型现已全面接入 Qwen API,面向开发者与企业用户开放调用,标志着AI语音生成从“选音色”迈向“造声音”的全新阶段。
Qwen3-TTS-VD-Flash:用语言“雕刻”你的专属声音
告别传统TTS系统中千篇一律的预设音色库。Qwen3-TTS-VD-Flash 让你仅凭自然语言描述,就能生成独一无二的声音形象。无论是“低沉缓慢、带着一丝沙哑的侦探旁白”,还是“轻快明亮、语调上扬的儿童故事讲述者”,甚至是“像BBC纪录片 narrator 那样冷静克制,但又带点人文温度”的语感,只需一句话,模型就能精准还原。
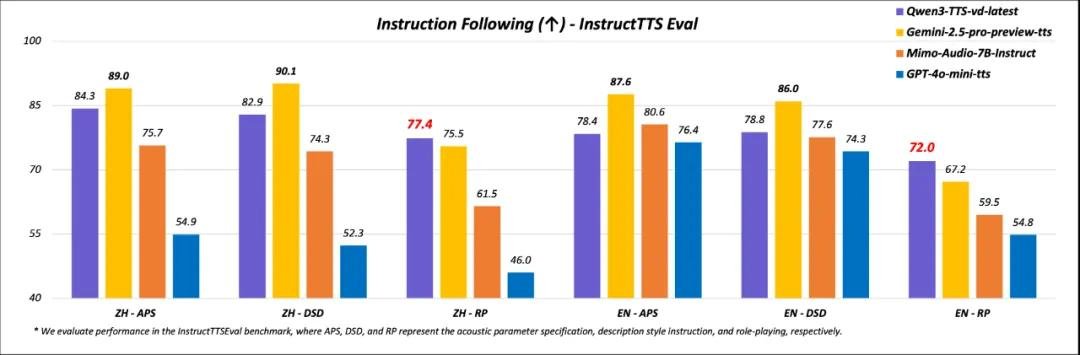
在权威评测 InstructTTS-Eval 中,Qwen3-TTS-VD-Flash 在角色表现力、情感一致性与语义适配三项核心指标上全面超越 GPT-4o-mini-tts 和 Mimo-audio-7b-instruct。尤其在“角色扮演”类任务中,其表现甚至优于 Gemini-2.5-pro-preview-tts,能稳定输出具有鲜明个性的对话角色,为有声书、虚拟主播、智能客服等场景带来前所未有的沉浸感。
Qwen3-TTS-VC-Flash:3秒克隆,10语种无缝生成
只需一段3秒的真人语音样本,Qwen3-TTS-VC-Flash 即可完成高保真声音克隆,复刻音色、语调、口音甚至呼吸节奏。更重要的是,它支持中文、英文、日语、韩语、法语、德语、西班牙语、意大利语、葡萄牙语、俄语共10种主流语言的语音合成——这意味着你可以用中文原声,直接生成一口流利的日语广告配音,或让英文母语者的音色说出地道的德语演讲。
在 MiniMax TTS 多语言测试集上,Qwen3-TTS-VC-Flash 的平均词错误率(WER)显著低于 ElevenLabs、MiniMax 以及 GPT-4o-Audio-Preview。在跨语言迁移场景中,其内容稳定性优势尤为突出——即使源语音与目标语言语义结构差异巨大,也能保持语音自然、语义准确,极大降低多语种内容生产的成本与门槛。

不止于“像”,更懂“怎么说”
这两款模型的共同突破,在于真正理解了“语音不是机械播放,而是情绪的流动”。它们能根据文本内容自动调整语速节奏、呼吸停顿、重音分布——比如在读到“他停顿了一下,深吸一口气”时,语音会自然留白;在描述紧张情节时,语速会加快、音调微颤,仿佛真人临场演绎。
面对长句、专业术语、标点混乱的文本,Qwen3-TTS 依然能准确识别语义重心,避免“机器人式断句”或“机械重复”。无论是电商直播的促销话术、法律文书的朗读、还是诗歌朗诵的韵律处理,都能流畅自然,大幅降低后期剪辑成本。
从“复刻”到“创造”,语音应用的想象力正在重启
过去,语音合成要么只能“模仿”,要么只能“选择”。如今,Qwen3-TTS-VD-Flash 让你“创造”声音,Qwen3-TTS-VC-Flash 让你“复刻”人声——两者结合,意味着内容创作者可以:用AI生成一个专属品牌声音,贯穿所有产品宣传;让虚拟偶像拥有独一无二的声线,并跨语言全球发声;甚至为老年人克隆其已故亲人的声音,用于情感陪伴应用。
据行业分析机构 Counterpoint Research 数据显示,2025年全球AI语音合成市场规模将突破120亿美元,其中“个性化声音”与“多语言克隆”成为增长最快赛道。通义千问此次更新,不仅补齐了技术短板,更率先打开了“声音即服务”(Voice-as-a-Service)的新入口。
现在,你不再只是语音的使用者——你,是声音的设计师。