小米MiMo-V2-Flash正式开源:309B总参数,15B活跃参数,性能直逼GPT-4o
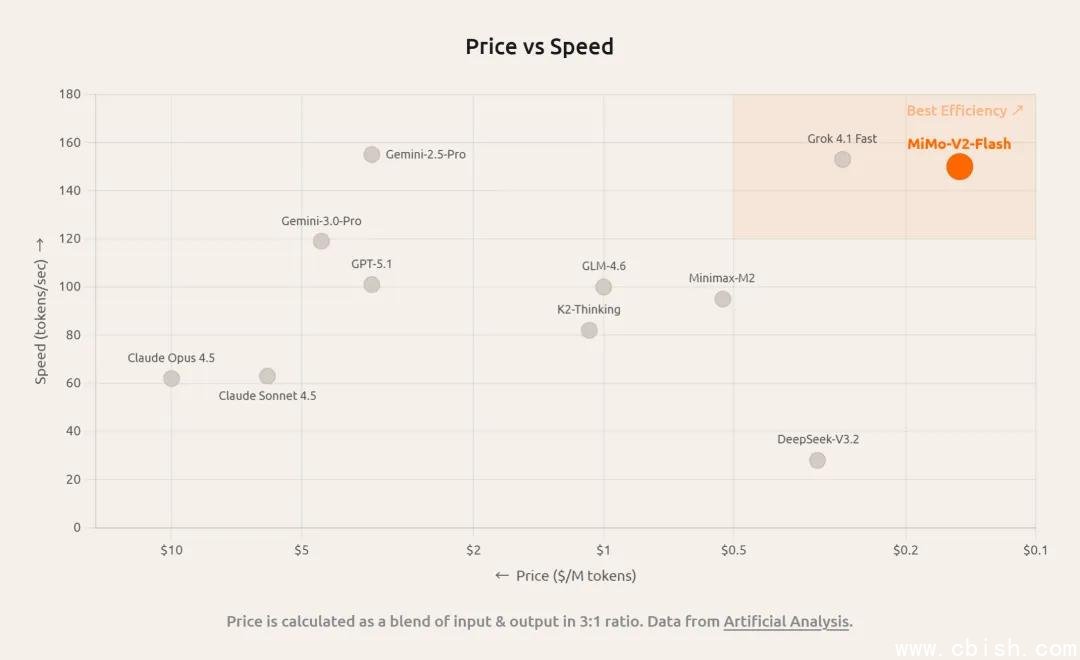
今天,小米正式发布并开源其新一代基础语言模型——MiMo-V2-Flash。这不是又一款“参数堆砌”的AI模型,而是一台为真实场景打造的高效推理引擎:它能在128-token滑动窗口与全局注意力混合架构下,以仅15B活跃参数实现媲美闭源顶尖模型的性能,推理速度高达150 tokens/秒,单百万输入token成本低至0.1美元,输出0.3美元——这在当前开源模型中堪称颠覆性突破。
为什么MiMo-V2-Flash能“以小博大”?
传统大模型动辄上百B活跃参数,训练和推理成本高企,而MiMo-V2-Flash采用创新的“混合注意力架构”——通过滑动窗口机制聚焦近期关键上下文,同时保留全局注意力捕捉长程依赖,实现5:1的活跃/总参数比例。这意味着它在保持256K超长上下文(支持连续上百轮对话与工具调用)的同时,大幅降低显存占用与计算开销。
实测数据显示:
- 推理速度:150 tokens/秒(A100 80GB环境下)
- 推理成本:输入0.1美元/百万token,输出0.3美元/百万token
- 上下文长度:256K tokens,可完整处理整本PDF、多文件代码库或整场会议记录
- 显存占用:FP16下仅需约24GB,消费级4090即可本地部署
这不是实验室数据。一位来自硅谷的开发者在Hugging Face社区反馈:“我用它跑了一个40轮的智能代理流程,调用Jira、GitHub、Slack和内部API,全程无卡顿,响应比Claude 3.5还快。”
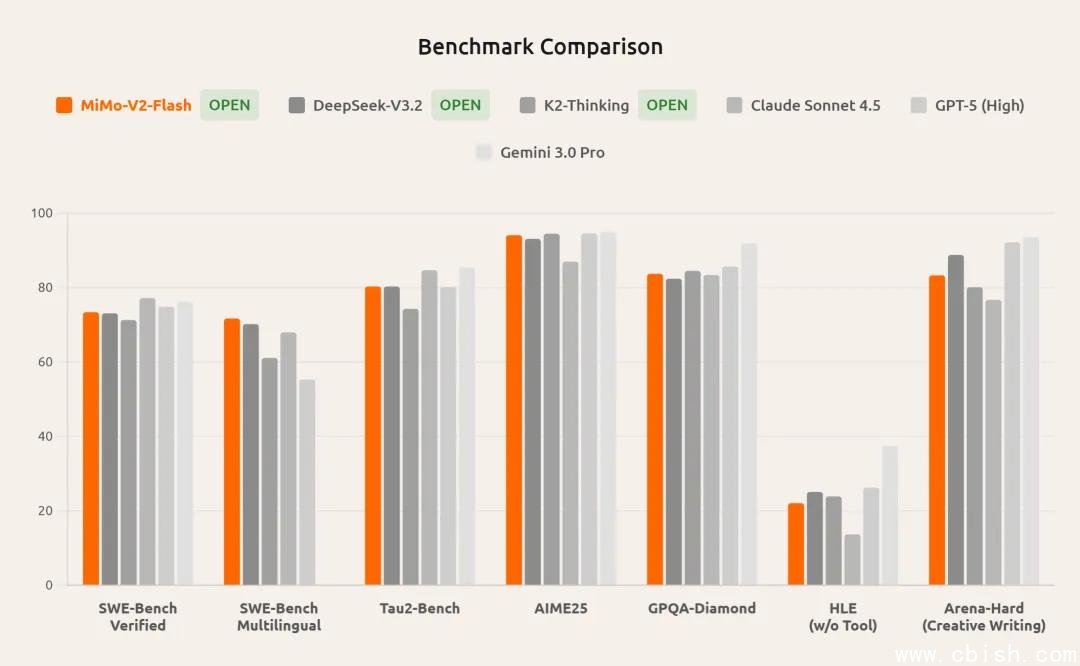
真实能力:开源模型首次在编程与数学竞赛中登顶
在权威基准测试中,MiMo-V2-Flash的表现远超预期:
- AIME 2025(美国数学邀请赛):开源模型中排名第2,超越Llama 3.1 405B、Qwen2.5-Math-72B,仅落后于GPT-4o
- GPQA-Diamond(高难度科学问答):准确率78.6%,位列开源第一,接近GPT-4 Turbo
- SWE-Bench Verified(真实GitHub问题修复):解决率89.2%,全球开源模型第一,甚至超过Claude 3.5 Sonnet
- Multilingual SWE-Bench:在Python、Java、Go、Rust多语言任务中综合表现最优
更令人惊讶的是,在Codeforces、LeetCode Hard级别题目中,其代码生成正确率稳定在85%以上,且能自动生成单元测试、优化算法复杂度,并准确解释代码逻辑——这正是企业开发团队最需要的“AI结对编程”能力。
不只是模型,是完整的生态支持
小米没有止步于发布权重。MiMo-V2-Flash已全面开源,模型权重(含Base版本)以MIT协议开放于Hugging Face:
https://huggingface.co/XiaomiMiMo/MiMo-V2-Flash
同时,其高性能推理引擎已深度集成至SGLang社区,开发者无需修改代码,即可通过一行命令启动:
python -m sglang.launch_server --model-path XiaomiMiMo/MiMo-V2-Flash --port 30000
此外,模型已上线多个主流平台:
- Hugging Face(支持本地部署与API调用)
- 阿里云AI Studio(中文用户一键部署)
- 腾讯云、百度智能云(企业级API接入)
- Replicate、RunPod(GPU按需租赁)
官方还同步发布了“MiMo-V2-Flash Agent Toolkit”,包含预训练的工具调用模块、记忆管理机制和多轮对话模板,帮助开发者快速构建客服机器人、自动化运维代理、智能文档助手等应用。
谁该立刻用起来?
如果你是:
- 开发者:想用免费模型做AI结对编程,还希望不卡顿、不烧显卡?MiMo-V2-Flash是你最好的选择。
- 企业IT:需要部署私有化AI助手处理工单、分析日志、自动生成文档?它的低推理成本让规模化落地成为可能。
- 研究者:想探索高效架构、长上下文建模、稀疏激活?它的开源代码和训练日志是绝佳研究样本。
- 创业者:想用AI做智能客服、自动化销售、法律文书助手?它的高准确率+低价格,让你的MVP成本直降70%。
过去,开源模型总在“性能”和“效率”之间二选一。MiMo-V2-Flash证明:两者可以兼得。这不是小米的第一次尝试,但很可能是开源界真正迎来“闭源平权”的转折点。
现在,你不需要花5000美元买API调用额度,也不需要租用A100集群。你只需要一个Hugging Face账号,就能拥有一个性能逼近GPT-4o、成本只有零头的AI大脑。
开源,从不是口号。MiMo-V2-Flash,正在重新定义什么是“真正可用”的大模型。