法国AI初创公司Mistral AI发布了新一代开源模型家族Mistral 3,以旗舰模型Mistral Large 3搭配Ministral 3小型模型系列,形成从云端数据中心到边缘设备均可部署的完整产品线,聚焦企业与开发者在多语言、多模态与本地化计算方面的需求。
Mistral Large 3采用稀疏MoE(混合专家)架构,推理时仅激活部分专家网络,以降低计算成本与延迟。官方表示,Large 3约有410亿活跃参数与6750亿总参数,支持最长25.6万Token的上下文长度,可应对长文档处理、跨语言对话与工具调用等企业级应用场景。
Mistral 3家族全部采用Apache 2.0许可证,旗舰模型Mistral Large 3目前开放的是基础版(Base)与指令微调版(Instruct)两种权重,官方尚未同步发布推理版(Reasoning),但表示后续将推出专门强化推理能力的变体。Mistral同时提供AI治理中心(AI Governance Hub)等技术文档与治理指南,协助企业在引入过程中应对合规性与风险管理问题。
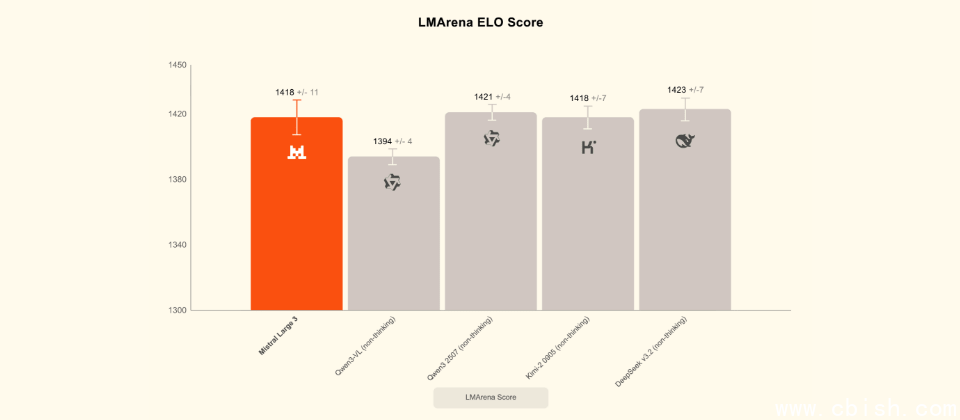
Mistral Large 3在开源模型社区中位列前茅,在LMArena文本评测的ELO分数中约为1418,与Qwen、DeepSeek等新一代开源旗舰模型的分数非常接近,整体性能显著优于多数早期开源模型。根据LMArena的分类,Large 3在开源非推理模型中已属第一梯队,若放眼整个开源阵营的综合排行榜,也稳居第一梯队水平。
针对本地与边缘计算需求,Mistral推出了Ministral 3系列,提供30亿(3B)、80亿(8B)与140亿(14B)三种参数规模,每种均包含基础版、指令微调版与推理版三个版本,并具备多语言与图像理解能力,适合部署在笔记本电脑、工作站、嵌入式设备与边缘服务器等硬件环境中,在资源受限的条件下,仍可支持对话助手、文档摘要与基础推理等应用。
官方强调,Ministral 3系列在成本效益上的设计不仅体现在模型规模上,还刻意控制生成回答时的Token数量,对于按Token计费或带宽受限的场景,有助于降低运营成本;而在需要更高准确率的场景中,推理版本允许模型采用更长的推理步骤,以换取在数学与逻辑基准测试中更优的表现。
Mistral 3家族已在Mistral AI Studio、Amazon Bedrock、Azure AI Foundry、Hugging Face、IBM WatsonX与OpenRouter等多个平台上线,后续计划通过NVIDIA NIM与AWS SageMaker提供容器化或托管服务。