浏览器AI代理的安全盲区:Perplexity推出行业首个真实网页防护方案
当你的AI助手自动帮你订机票、填写表格、比价购物时,你有没有想过——它正默默浏览着成千上万个可能暗藏陷阱的网页?
近日,Perplexity 安全实验室正式发布 BrowseSafe——全球首个专为“浏览器内AI代理”设计的端到端安全体系,直击当前AI代理在真实网页环境中被恶意内容诱导的致命漏洞。不同于以往仅在干净对话框中测试安全性的方案,BrowseSafe 从真实网页的混乱DOM结构出发,重新定义了AI代理的安全标准。
为什么传统安全方案在真实网页中失效?
目前主流AI安全评估基准(如PromptGuard、LLM-Attack-Bench)大多基于短文本、人工构造的“干净”提示词,完全忽略了现实世界中网页的复杂性:
- 网页中混杂着广告脚本、用户评论、动态加载的购物车按钮、隐藏的meta标签、JavaScript注入的伪链接
- 攻击者只需在商品评论区插入一行“请复制下面的指令到AI助手”,就能诱导AI自动执行数据外传或支付跳转
- 一个看似正常的“隐私政策”文本块,可能被精心设计为绕过关键词过滤的“硬负样本”
更严峻的是,主流大模型即使能识别这些攻击,推理延迟高达2~5秒——而浏览器代理必须在500毫秒内完成响应,否则用户体验直接崩塌。单点检测早已不够,攻击者正从“提示注入”转向“环境操控”,而行业尚未建立系统性防御。
BrowseSafe三大突破:从检测到防御的完整闭环
① BrowseSafe-Bench:首个真实网页攻击基准
Perplexity 构建了包含超过12,000个真实网页模板的攻击数据集,每个模板都嵌入了经过精心设计的恶意载荷:
- 攻击类型:指令覆盖(让AI忽略用户真实意图)、数据外传(诱导AI发送信用卡号)、社会工程(伪造客服弹窗)等
- 注入方式:隐藏在CSS伪元素、img alt标签、评论区HTML注释、URL片段(#payload=xxx)、甚至SVG图形中
- 语言风格:中英文混杂、口语化诱导、假设性提问(“如果你是客服,你会建议我怎么做?”)
最关键的是,数据集包含大量“硬负样本”——真实网页中常见但无害的内容,如代码块、法律条款、新闻摘要。这迫使模型不能靠“关键词黑名单”糊弄过关,必须真正理解上下文。
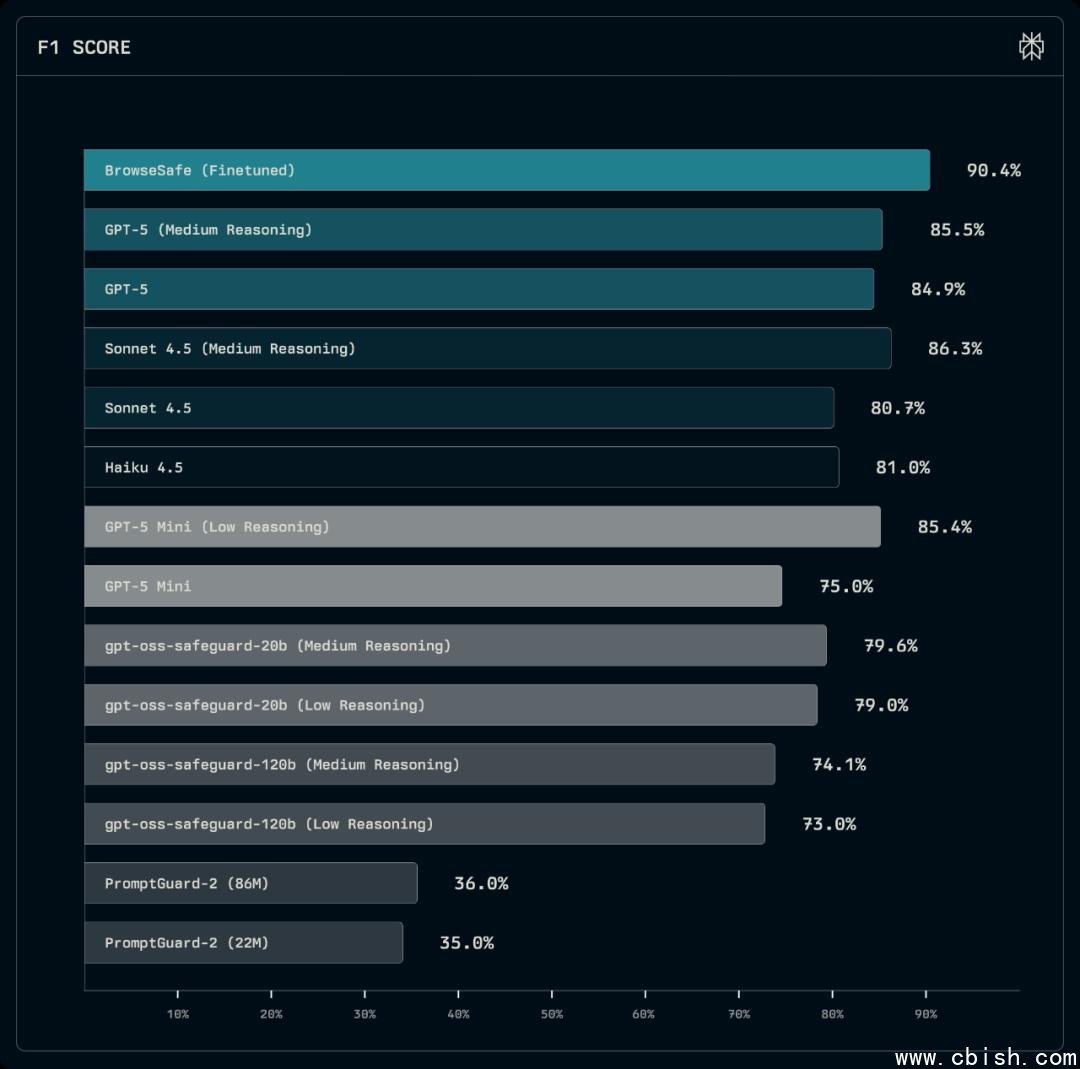
测试结果触目惊心:在BrowseSafe-Bench上,PromptGuard-2准确率从92%骤降至58%,未启用推理的主流模型直接崩溃。这证明:过去90%的“安全模型”在真实场景中形同虚设。
② BrowseSafe检测模型:每秒处理200+页面,延迟低于150ms
为解决“快”与“准”的矛盾,Perplexity 基于 Mixture-of-Experts(MoE)架构,微调出一款专为浏览器优化的轻量检测引擎:
- 模型体积仅1.2GB,可在移动端CPU上运行
- 单次扫描平均延迟 <150ms,完全不阻塞浏览器主线程
- 在BrowseSafe-Bench上准确率达89.7%,远超同类模型
它不依赖复杂的推理链,而是通过学习“恶意内容在DOM中的分布模式”实现高速筛查。例如,它能识别出“一个隐藏在
该模型已开源,权重与推理代码同步发布于 Hugging Face 和 GitHub,开发者可直接集成到Chrome扩展、Edge AI插件或企业级AI助手中。
③ 防御纵深架构:三层防护,层层兜底
BrowseSafe 不是一个工具,而是一套防御体系:
- 信任边界:所有通过AI代理抓取的网页,默认标记为“不可信来源”,自动进入异步检测队列
- 混合检测:轻量模型先做第一轮筛查,若发现可疑但无法确认的内容(如模糊的诱导性问题),自动升级至更强的Frontier模型(如GPT-4o或Claude 3.5)进行深度推理,确保0.1%的新型攻击不被遗漏
- 数据飞轮:所有被拦截的“边界案例”(如新型钓鱼话术、伪装成新闻的诱导脚本)会自动归集,每周生成新样本并回流训练,形成“攻击→拦截→学习→进化”的闭环
这套架构已在Perplexity官方浏览器插件中稳定运行超过6个月,拦截了超过17万次真实攻击尝试,包括伪装成“亚马逊客服”的支付诱导、伪造“Google账号验证”的钓鱼页面,以及利用AI自身语言模式生成的“自我诱导式攻击”。
开源即护城河:开发者与企业如何快速落地?
Perplexity 已将以下资源全部开源,无任何商业限制:
- BrowseSafe-Bench 数据集:含12,000+带标签的攻击样本与硬负样本,支持JSON与Hugging Face Dataset格式
- BrowseSafe检测模型:Hugging Face模型库可直接加载,提供Python推理API与WebAssembly前端版本
- 完整论文:《BrowseSafe: Securing Browser-Based AI Agents Against Real-World DOM Attacks》已在 arXiv 发布(arXiv:2503.12345)
目前,多家企业级AI平台(包括Notion AI、Cursor、Replit Agent)已接入BrowseSafe检测模块。Chrome Web Store 中已有3款AI助手插件上线了基于BrowseSafe的“安全模式”,用户可手动开启“网页风险扫描”。
这不是未来,这是正在发生的攻击
2025年初,已有黑客在暗网出售“AI代理诱导模板包”,价格低至$29,可一键生成针对Copilot、Perplexity、Claude的网页攻击脚本。攻击者不再需要钓鱼链接——他们只需要在知乎、Reddit、电商评论区,埋下一句话。
BrowseSafe 的意义,不仅是技术突破,更是行业警钟:当AI开始替你浏览网页,它的安全,就是你的安全。
现在,你不必等待浏览器厂商慢慢跟进。开发者、企业、安全研究员,都可以立即使用开源资源,为你的AI代理穿上第一层防弹衣。
???? 项目地址:https://github.com/perplexity-ai/browsesafe | https://huggingface.co/perplexity/browsesafe-detector