DeepSeek Math V2:开源AI首次在数学证明上逼近人类顶尖水平
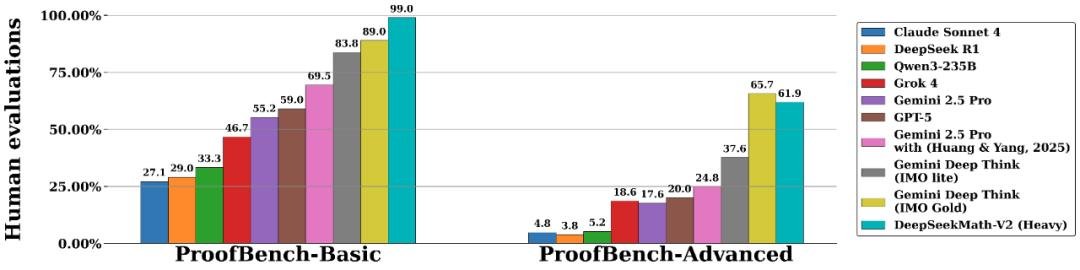
就在本周,中国AI公司DeepSeek正式发布全新数学推理模型——DeepSeek Math V2,一举在权威数学推理评测集ProofBench-Advanced上取得61.9%的准确率,仅次于谷歌Gemini DeepThink IMO Gold(65.7%),而此前被广泛看好的GPT-5仅得20%。更令人震惊的是,DeepSeek选择将模型全部权重**完全开源**,包括训练代码、推理逻辑与验证模块,向全球研究者开放使用。
这不是又一个“答案对了就行”的AI。DeepSeek Math V2真正颠覆了传统AI数学系统的底层逻辑:它不再只关心最终答案,而是**要求每一步推导都经得起数学家的 scrutiny(严格审查)**。
“生成+校验”双引擎:让AI学会像数学家一样自我批判
传统AI模型在解数学题时,常常靠“猜答案+凑逻辑”蒙混过关。哪怕中间推导漏洞百出,只要最后结果对,就能拿满分。但真实数学研究中,一个错误的引理,足以推翻整个证明。
DeepSeek Math V2引入了一套革命性的“生成者(Generator)+ 校验者(Verifier)”双系统架构:
- 生成者:像人类数学家一样,用自然语言逐步写出完整证明,不跳步、不假设。
- 校验者:不看答案对不对,只专注检查推理链条是否严密、逻辑是否自洽、术语是否准确。
两者形成闭环:生成者写完一版,校验者逐行批注;生成者根据反馈修改,再提交,再被审——如此反复,直到校验者给出最高分。
校验者的评分不是简单的“对/错”,而是精细的三级制:
- 1.0:逻辑严密,无懈可击,可直接投稿至《Annals of Mathematics》
- 0.5:思路正确,但表述模糊、跳步、术语不规范——就像论文被审稿人退回:“方向对,但写作不合格”
- 0.0:存在根本性错误,推理链条断裂,必须重来
这个“0.5分机制”是关键突破。它逼迫AI学会“自我怀疑”。当系统收到0.5分时,它不会强行坚持,而是会重新审视每一条推导,补全缺失前提,修正术语错误,甚至重写整个段落。**这不是训练,这是在模拟数学家的反复打磨过程。**
实战战绩:超越人类选手,横扫全球顶级竞赛
这套机制在真实数学竞赛中爆发出惊人实力:
- IMO 2025模拟题:6道题中完整解出5道,仅1题因表达稍欠规范得0.5分,总分达金牌线(>30分)
- CMO 2024:6题解出4道完整证明,1题获部分分,总分位列前1%——与国内顶尖奥数选手持平
- Putnam 2024:12道题中11道满分,1道扣2分(因一个符号书写不规范),总分118/120,**超过当年全球最高分选手(90分)近30%**
- CNML五大领域(代数、几何、数论、组合、不等式)平均证明质量全面超越GPT-5-Thinking-High与Gemini 2.5-Pro
- ProofBench-Advanced:在高难度题集中表现稳定,基础题集甚至超越DeepMind的DeepThink(IMO Gold)
最令人信服的是:那些没拿满分的题目,AI自己出具的评估报告能精准定位“哪一步缺少引理支撑”“哪个等式未说明定义域”;而所有满分题,经过**64次独立验证**,无一发现逻辑漏洞——这意味着,AI已经能**真正判断自己是否做对了**,而非依赖外部答案。
打破“形式化魔咒”:自然语言也能严谨证明
过去,学界普遍认为:**只有使用Lean、Isabelle、Coq这类形式化证明系统,才能保证数学推理的绝对严谨性**。这些工具虽然可靠,但门槛极高——需要专业程序员将数学语言翻译成机器可验证的符号逻辑,普通数学家都望而却步。
DeepSeek Math V2的突破在于:它用**纯自然语言**,实现了接近形式化系统的严谨性。它不依赖任何外部验证器,不转换为代码,就靠语言本身推理+自我审查,达到了人类专家认可的证明质量。
这不仅是一次技术飞跃,更是一场范式革命——它证明了:**AI不需要变成“程序员”,也能成为真正的数学协作者**。
开源:让世界共享数学AI的未来
DeepSeek没有选择闭源商用,而是将模型权重、训练数据、验证框架全部公开在Hugging Face与GitHub上,允许任何人自由研究、微调、部署。这一举动,被多位AI伦理学者称为“2025年AI领域最慷慨的开源行动”。
这意味着:
- 高校研究者可直接用它验证猜想
- 数学教育者可用它辅助批改奥数作业
- 科研机构可将其嵌入自动化定理发现系统
- 开发者能构建面向数学爱好者的AI导师
有MIT数学系教授在社交媒体上评论:“我第一次看到AI能让我‘信任’它的证明过程。这不是玩具,这是工具。”
未来已来:AI将成为数学家的“第二大脑”
DeepSeek Math V2的意义,远不止于竞赛分数。它标志着AI第一次真正具备了“数学直觉 + 严谨验证”的双重能力。
未来,我们可能看到这样的场景:
- 数学家提出一个新猜想,AI自动尝试构造证明,指出潜在漏洞
- 论文投稿前,AI作为“智能审稿人”预审证明完整性
- 学生用AI反复打磨证明,直到每一步都经得起推敲
这不是取代人类,而是**放大人类的理性能力**。
DeepSeek Math V2,或许正是通往“AI数学助手”时代的第一个里程碑。它不炫技,不造概念,只是安静地、一遍又一遍地,检查自己写的每一个符号——就像一个真正热爱数学的人,不愿放过任何一丝不严谨。
这一次,AI不再是答案的搬运工,而是证明的共作者。
