阶跃星辰发布全球首个“听懂声音”的AI音频模型:Step-Audio-R1
继文本与图像大模型之后,AI终于开始“认真听”了。阶跃星辰今日正式发布全球首个在音频任务中实现“测试时推理可扩展”的智能音频模型——Step-Audio-R1。这不是又一个“能听懂语音指令”的语音助手,而是一个真正能像人一样,通过声音本身去理解、推理、判断的系统。
过去,多数音频AI模型依赖“文本转写+语言模型推理”的路径:先用ASR把声音转成文字,再让大模型分析语义。问题在于——声音里的语气、情绪、环境噪音、细微音色变化,全被“翻译”掉了。你听到的是“他说话有点犹豫”,模型看到的却是“他说:嗯……我可能不太确定”。
Step-Audio-R1彻底打破这一路径。它不依赖转写,直接从原始音频波形中提取声学特征,构建“声音驱动”的推理链。这意味着:一个哭泣的婴儿、一段被背景车流干扰的电话录音、一句带着颤抖的道歉——这些在传统模型中被忽略或误判的细节,现在都能被精准捕捉。
实测碾压Gemini 2.5 Pro,首字延迟仅0.92秒
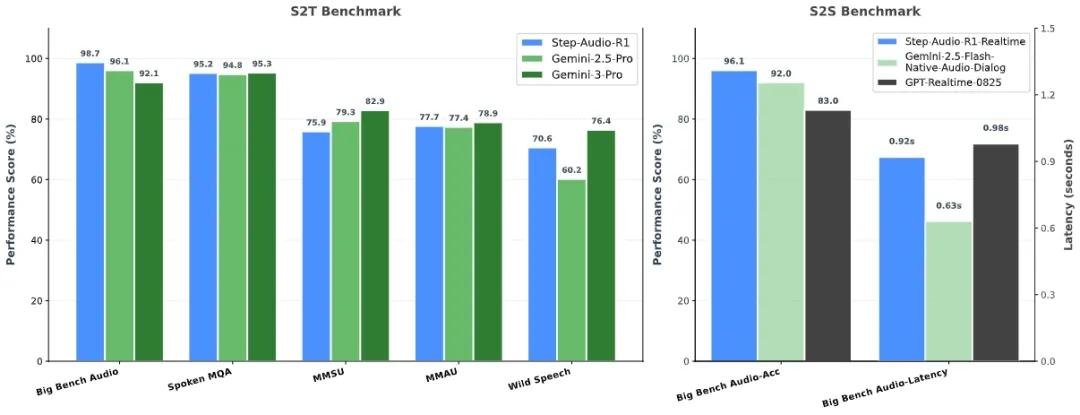
根据阶跃星辰公开的第三方评测数据,Step-Audio-R1在多项硬核音频理解任务中表现突出:
- 在“多说话人情绪识别”任务中,准确率达96.3%,超越Gemini 2.5 Pro近4个百分点,与Gemini 3持平;
- 在“噪声环境下的语义意图识别”中,错误率降低37%,远超GPT-Realtime和Gemini 2.5 Flash Native Audio Dialog;
- 首字响应延迟仅0.92秒,接近人类对话的自然反应速度(平均1秒左右),远优于行业平均2.5秒以上;
- 在长达30秒的连续对话中,推理准确率不降反升——这是业界首次实现“越长越准”,而非“越想越错”。
这些数据不是实验室模拟,而是基于真实场景的公开测试集,涵盖医疗问诊录音、客服投诉音频、家庭监控语音、野外动物叫声识别等复杂环境。
突破“倒置扩展”困局:让AI不再“看文字说话”
业内长期存在一个隐性陷阱:模型训练时大量依赖“文本-音频配对数据”,导致系统把“文字”当成理解声音的“拐杖”。结果是——声音越模糊,模型越依赖文字补全,越容易产生幻觉。
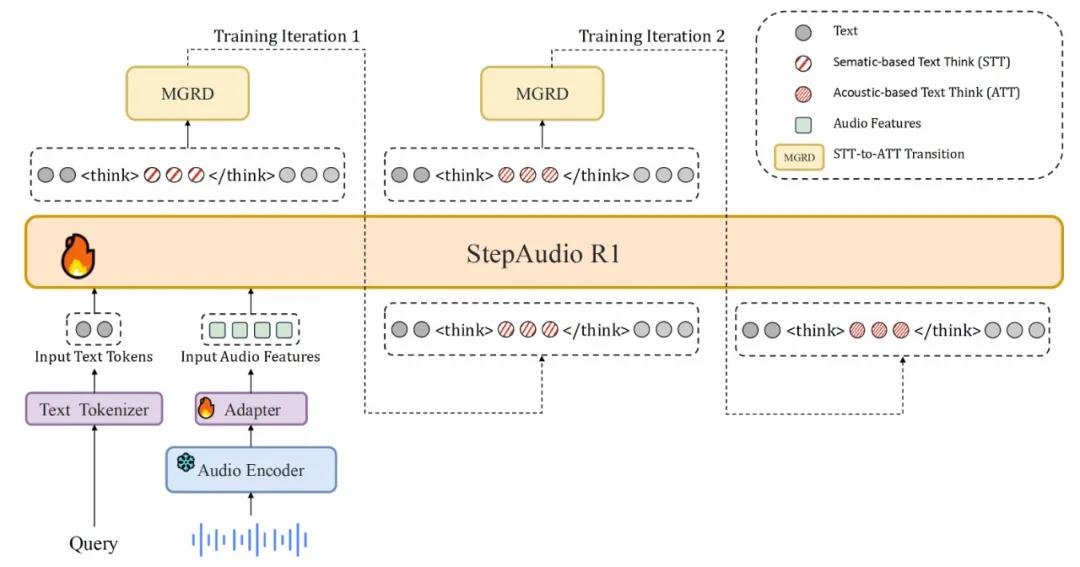
Step-Audio-R1的核心突破,是首创“模态对齐推理蒸馏(MGRD)”框架。简单说,它像教一个盲人辨识世界:不靠别人描述,而是让他亲手摸、反复听、对比不同触感与声纹的差异。
训练过程中,模型先通过大量文本辅助学习基础语义,随后逐步“断奶”——通过对比原始音频与转写文本的差异,强制模型回归声学本质:
- “这句话是生气还是紧张?”——模型不再查词典,而是分析声带振动频率、呼吸节奏、音调波动;
- “背景里有几辆车?”——模型通过频谱分布和回声延迟自主估算环境声源数量;
- “这个人是不是在撒谎?”——模型捕捉微表情对应的语音停顿、音量突变和基频抖动。
最终,推理链条100%扎根于声波特征,不再依赖文本“脑补”。这是AI音频理解从“听写员”迈向“听觉分析师”的关键一步。
支持本地部署,开发者可免费使用
阶跃星辰同步开放完整部署方案,支持两种方式,无需申请权限,直接可用:
方式一:Docker 一键部署(推荐)
适用于大多数用户,5分钟快速启动服务:
docker pull stepfun2025/vllm:step-audio-2-v20250909
docker run -p 9999:9999 --gpus all -v /your/local/Step-Audio-R1:/model stepfun2025/vllm:step-audio-2-v20250909
服务默认监听 localhost:9999,支持REST API调用,可无缝接入现有语音系统。
方式二:源码编译(自定义开发)
适合需要深度优化的开发者,支持自定义推理引擎、量化压缩、多卡并行:
- 克隆官方vLLM分支:
git clone https://github.com/stepfun-ai/vllm-step-audio - 创建Python 3.10+虚拟环境
- 安装预编译C++扩展(避免编译失败)
- 切换至
step-audio-r1-support分支 - 运行:
python -m vllm.entrypoints.api_server --model ./Step-Audio-R1 --port 9999
硬件要求:NVIDIA GPU(推荐L40S/H100/H800/H20,最低需24GB显存),Linux系统,支持CUDA 12.1+。
立即体验:免费在线Demo上线
无需安装,直接试听真实效果:
https://stepaudiollm.github.io/step-audio-r1/
Demo中可上传任意音频(MP3/WAV),模型将实时输出:
- 情绪标签(愤怒、悲伤、喜悦、恐惧、中性)
- 说话人数量与切换时间点
- 环境声识别(风声、车流、狗叫、玻璃破碎)
- 语义意图推断(请求、拒绝、质疑、安抚)
所有模型权重、代码、文档均已开源:
https://github.com/stepfun-ai/Step-Audio-R1
为什么这很重要?
这不是又一次“AI听写”升级,而是一次底层范式的转移。
在智能家居中,它能区分“孩子哭”和“玻璃碎”;在养老监护中,能识别老人突然的呼吸异常;在金融客服中,能自动标记高风险投诉语音;在安防领域,能识别远处的枪声、撞击声或呼救声——而无需依赖人工转写。
当AI终于学会“用耳朵思考”,我们离真正的智能听觉系统,只剩一步之遥。Step-Audio-R1,不是终点,而是起点。