无人指导,零数据起步:斯坦福Agent0如何让AI自己“学会学习”
如果一个AI智能体,从零开始,没有人类给它示例、没有训练数据、没有人工反馈,它能自己变强吗?斯坦福大学一个低调但极具颠覆性的团队,用一个叫 Agent0 的系统给出了令人震惊的答案:能,而且它成长的速度,远超预期。
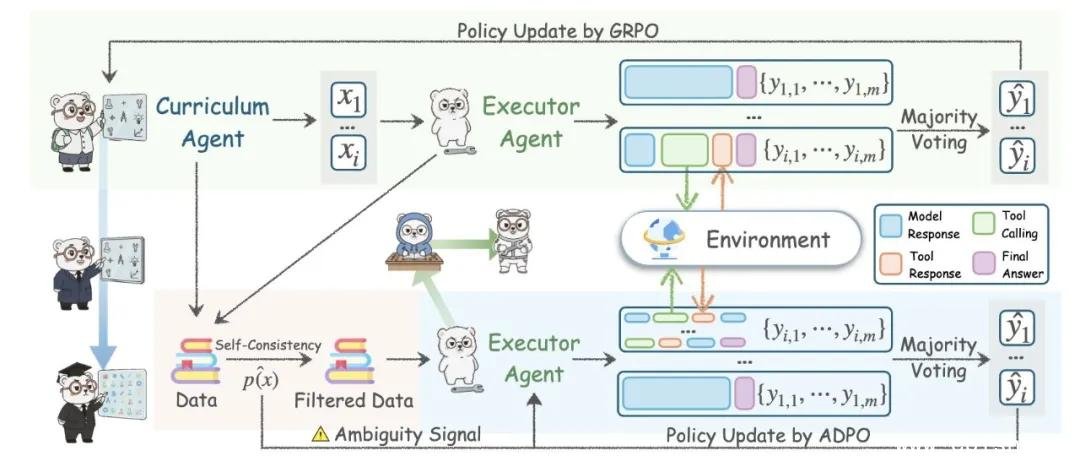
这不是简单的“自我训练”,而是一场由两个AI智能体共同导演的“认知军备竞赛”。系统内部分为两个角色:一个是“课程设计师”——课程智能体,负责不断出题;另一个是“解题者”——执行智能体,负责破解难题。两者没有外部干预,全靠彼此推动。
起初,题目很简单:求三角形面积、解一元方程。但每当执行智能体成功解决一道题,课程智能体就会立刻调整策略——出一道更难的。不是随机加难,而是精准识别执行智能体的薄弱点,针对性升级:从代数跳到数论,从逻辑推理跃入组合优化,甚至设计出需要多步工具调用才能破解的“陷阱题”。
真正的突破:让AI学会“动手做”
Agent0 的核心创新,不在于算法多复杂,而在于它允许执行智能体“真刀真枪”地操作现实世界工具——它能直接调用 Python 解释器写代码、运行程序、分析输出结果,并用这些结果反哺下一轮推理。
这意味着,当题目变成“找出1000以内所有满足特定同余条件的素数”时,执行智能体不会空想,而是直接写一段循环+筛法代码,运行后看结果,再根据输出调整策略。课程智能体也迅速跟进,开始设计那些“必须用代码验证”的问题——比如生成随机图并判断其是否为哈密顿图,或求解高维约束优化问题。
这不是模拟,是真实执行。每一次运行,都是对推理能力的一次淬炼。
结果惊人:超越所有已有方法
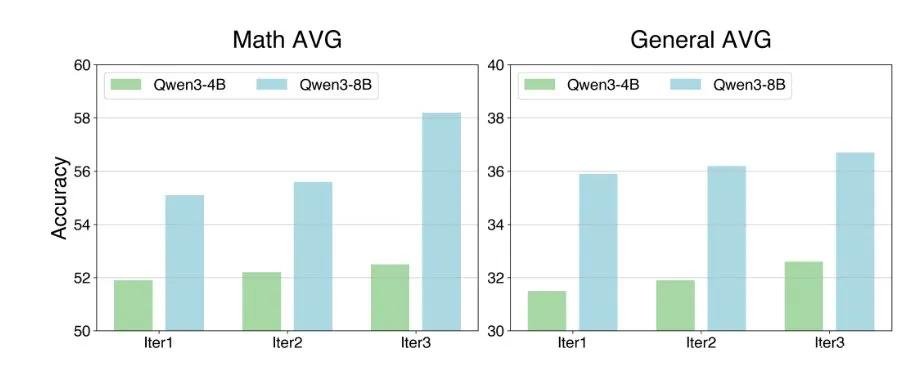
在完全不依赖任何预训练数据、不使用人类示范、不接入任何外部API的前提下,Agent0 在多个基准测试中实现了突破性表现:
- 数学推理能力提升 18%
- 通用推理能力提升 24%
- 综合表现超越 R-Zero、SPIRAL、Absolute Zero 等当前顶尖自监督框架
- 在部分复杂组合问题上,甚至击败了依赖 GPT-4 API 的闭源系统
更令人震撼的是,它的进步曲线是持续、稳定、非饱和的——随着训练轮次增加,题目难度从初中几何一路飙升至研究生级别的离散数学与形式验证问题。研究者在日志中记录到,系统曾自行设计出一道“用动态规划求解带时间窗的旅行商问题变体”,而这个问题在公开文献中也仅在近三年才有论文深入探讨。
这不是AI在“做题”,而是在“进化”
加州理工学院一位参与评审的教授评论道:“我们第一次看到一个系统,不是在模仿人类思维,而是在构建自己的认知路径。”
传统AI依赖海量数据和人类标注,而 Agent0 像一个在荒岛上独自成长的天才少年——没有课本,没有老师,只有不断出现的谜题和一把能运行代码的计算器。它没有“知道”答案,但它学会了“如何找到答案”。
这项研究的意义,远不止于提升AI的解题能力。它暗示了一种全新的AI发展范式:真正的智能,或许不需要“喂数据”,而需要“给挑战”。当系统能自我设限、自我突破、自我升级,我们离“自主认知系统”就不再遥远。
未来,Agent0 的机制可能被应用于机器人自主学习、科学发现自动化、甚至AI驱动的教育系统。它不靠人类教,它靠自己“活”出来。