Qwen3.6 27B 在 MacBook 上跑出 32 token/秒,智力分直逼 GPT-5
本地运行大模型再也用不着在性能上委曲求全。开发者 Piotr Migda? 在一台 MacBook Max M5 128GB 上对 Qwen3.6 27B 做了一次深度实测,结论很直接:这已经是一款能扛住通用智能需求、不必牺牲体验的本地工具。
先看效率。8-bit GGUF 量化版本,搭配 llama.cpp 服务,加上多 token 预测(MTP)和 flash attention 等优化,在 64K 上下文长度下稳在 32 tok/s。同一台机器上,35B A3B MoE 版本甚至能跑到 100 tok/s 以上。

更关键的在于智力水平。Artificial Analysis 给出的评分是 37 分,这个成绩直接对标 2025 年中期的 GPT-5 或 Claude Sonnet 4.5。而前一阵子很多开发者用作本地编码首选的 Gemma 4 31B,只有 29 分。也就是说,一年时间里,本地模型从两年前的“前沿”角色,一路追到了接近一年前顶级付费 API 的水平。
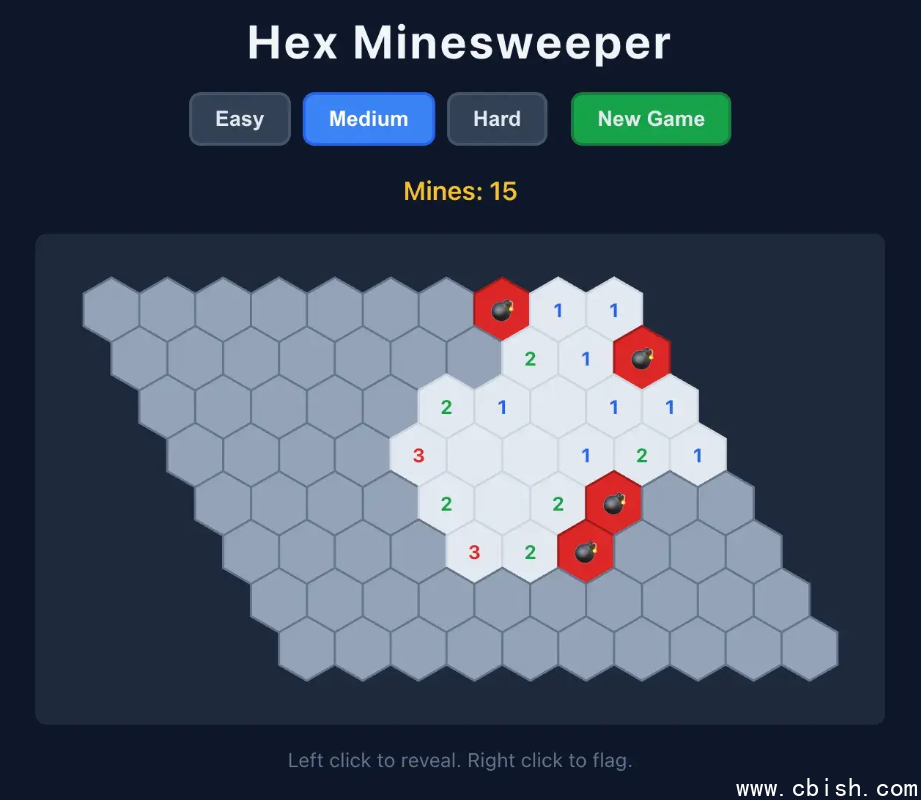
实际场景的测试同样扎实。写一首带复杂押韵要求的八行诗,或者用 pnpm 自动生成一个六边形扫雷游戏,Qwen3.6 27B 都能一次性交出高质量结果。对开发者来说,本地模型最大的好处是掌控感——不存在服务被突然收回的问题,也不会产生成堆的 API 调用费,模型就安安静静躺在自己的硬盘上。
这个信号很明确:当消费级硬件跑起来的开源模型,智力已经能和顶级付费模型正面抗衡,开发者就有了把高性能 AI 真正嵌入个人工作流里的底气。对于看重生产力和隐私安全的创作者,这大概是眼下最值得跟住的技术选项之一。