富士通公开PHOTON架构,尝试降低大模型算力成本
大模型迭代加速,算力开销与处理效率成为行业焦点。富士通近期公开了PHOTON架构,目标是打破传统Transformer模型在复杂场景下的性能限制。
Transformer架构在处理长文本或高并发多查询任务时,需要频繁调取历史信息。密集的访存操作拉低了处理速度,也增加了GPU的计算压力。PHOTON的设计直接绕开了这一环节。
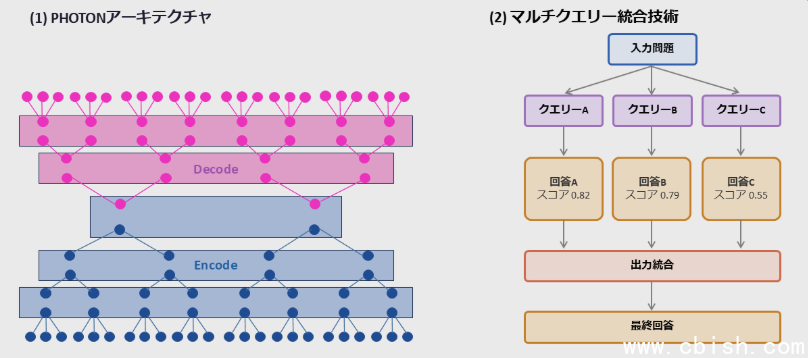
PHOTON的核心在于分层处理。它放弃了传统的词元切割方式,改用语义分层技术。计算复杂度随之降低,并行处理能力相应提高。面对多查询决策,架构通过多数决定或择优策略,只需一次推理即可输出结果。
测试数据表明,在600M、900M及1.2B参数的小型模型中,PHOTON保持了高吞吐量与低内存占用。1.2B参数模型的多查询性能达到主流Transformer架构的475倍。资源调度效率得到优化。
每次迭代所需的KV Cache减少,意味着系统能支持更多迭代次数。这对需要处理大量输入输出流程的智能体系统属于性能增益。部分指标存在轻微的质量折损,但计算效率的提升为降低AI运行成本提供了新方案。
富士通正推进该架构的应用落地。团队希望通过底层算法的改进,为后续的智能应用场景提供更轻量、高效的支撑。