防范第三方AI模型带来的供应链安全问题,思科近日开源模型溯源工具组(Model Provenance Kit),供企业识别模型来源,避免模型身份不明引发版权或其他安全与合规风险。
AI应用日益普及,许多企业从Hugging Face下载第三方AI模型,经过微调后用于开发AI应用。这些模型往往缺乏变更记录,无法追溯模型开发过程中所做的修改。使用此类模型可能面临多种风险,包括模型存在漏洞或被投毒、因模型谱系不明导致安全响应盲点,以及因来源不明引发的版权争议。此外,缺乏训练数据、训练方法和风险评估文档的模型,也无法满足《欧盟人工智能法案》(AI Act)的合规要求。
思科指出当前模型记录方式的不足。Meta、阿里巴巴、DeepSeek和Mistral等主要厂商均使用相同的构建组件,如分组查询注意力(Grouped-Query Attention)、旋转位置嵌入(Rotary Positional Embeddings)和均方根标准化(Root Mean Square Normalization, RMSNorm)等。虽然配置文件可描述这些架构,但无法判断模型是独立训练而来,还是从其他模型复制或衍生而来。为此,思科开源了其内部使用的AI模型溯源工具组Model Provenance Kit,旨在解决上述问题。
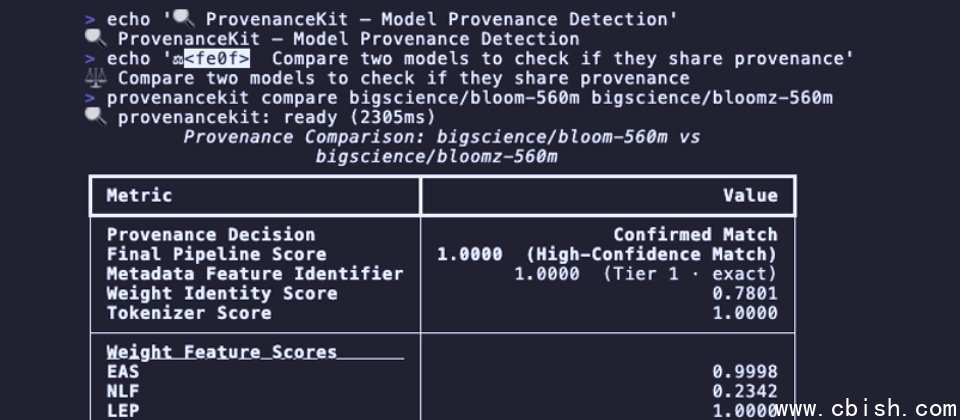
Model Provenance Kit是一个Python工具包和命令行界面(CLI),采用分层策略分析架构元数据、分词器(tokenizer)结构及其权重,以判断两个模型是否存在相同来源。第一步为快速检查结构,若元数据无法判断,则进入第二阶段深入分析权重层。
在第一阶段,该工具会比对模型的配置文件(config)及结构元数据。若架构规格完全不同,可判定为无关;若架构相同,则进入第二阶段的权重分析。在权重分析中,工具会从模型权重中提取五种信号或指纹,并加权整合为一个最终谱系评分。该工具支持两种比对模式:在比较模式(compare mode)中,需输入两个模型,可判断其中一个是否由抄袭或微调另一个模型而来;在扫描模式(scan mode)中,输入一个模型,系统将与数据库中的模型指纹进行比对,识别可能的来源模型。
思科使用111组模型对(model pairs)进行了系统性基准测试,验证Model Provenance Kit准确识别模型血缘关系的能力。测试结果表明,该工具能精准追溯模型来源,同时避免将架构相似但无血缘关系的模型误判为同源,具备实际可用的模型鉴识能力。
配合该溯源工具,思科同步发布了首个指纹数据库,涵盖20多家发布厂商、超过45个模型家族、近150个基础模型,模型参数规模从1.35亿到超过700亿,为模型比对提供权威基准。