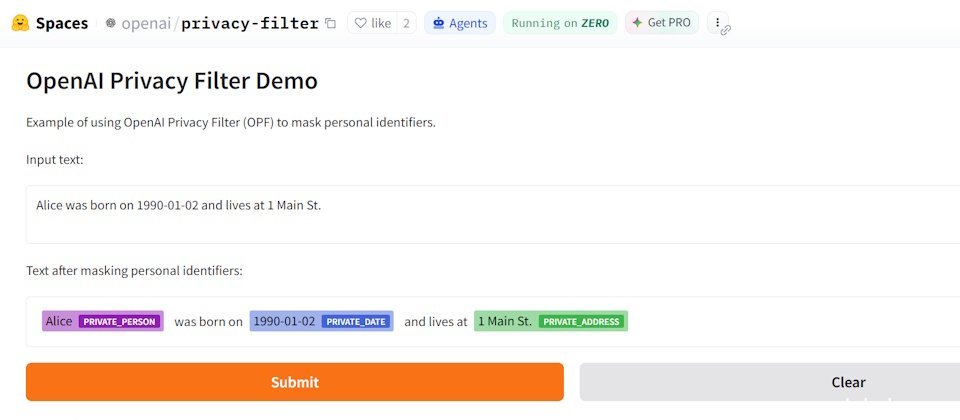
OpenAI于周二(4月22日)发布Privacy Filter,这是一款用于检测并遮蔽个人身份信息(PII)的开源权重模型,已在Hugging Face与GitHub公开发布,采用Apache 2.0许可证,支持开发者下载、部署和商业使用。该工具主打本地化运行,可在数据发送至云端或大型模型前完成去标识化处理。
随着生成式AI应用的广泛普及,企业面临的关键挑战之一是敏感数据在训练或推理过程中发生泄露。Privacy Filter的定位是在数据进入AI流程前主动过滤个人信息,属于“隐私优先设计”(privacy-by-design)的数据处理机制,有助于降低合规与安全风险。
在技术架构上,Privacy Filter基于OpenAI开源模型系列gpt-oss构建,不同于传统大型语言模型逐字生成的自回归方式,该模型采用双向Token分类架构,能够同时利用前后语境判断每个词是否属于个人信息。这一设计使其在识别需语义理解的信息(如姓名、日期)时,比依赖规则的传统工具更具准确性。
此外,模型采用稀疏混合专家(Mixture-of-Experts, MoE)架构,总参数约15亿,但每次推理仅激活约5000万参数,可在保持性能的同时显著降低计算成本。其支持12.8万个Token的上下文长度,可一次性处理长文档或多封邮件对话,避免分段处理导致的上下文断裂问题。
Privacy Filter可识别八类个人信息,包括姓名、地址、电子邮件、电话号码、网址、日期、账户信息与敏感凭证(如密码和API密钥),并通过序列标注与解码机制,确保遮蔽后的内容在语义上保持连贯。企业可将其部署于本地服务器或私有云,在数据进入如GPT-5等大型模型前完成清洗,以满足GDPR、HIPAA等法规要求。
对开发者而言,该模型可在笔记本电脑或浏览器中运行,并支持按需微调。Apache 2.0许可证允许企业将其整合至自有产品中,无需公开源代码或支付授权费用。
不过,OpenAI也提醒,Privacy Filter应作为辅助工具,而非完整的隐私保障方案。在医疗、法律与金融等高风险场景中,仍需配合人工复核,以降低漏判与误判的风险。