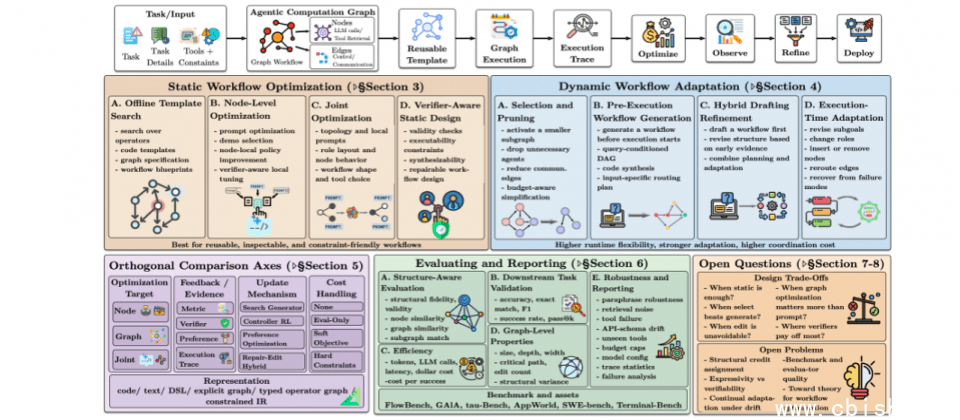
近年来,大型语言模型(LLM)已从单纯的对话工具,发展为能够执行多种任务的AI代理(Agent),许多企业也开始用其自动完成工作流程。然而,实际落地后,不同团队发现实现效果差异显著。
IBM最近发表了一项研究,指出这种关键差异并不在于模型本身,而在于整个流程的设计。
AI不只是回答问题,而是在跑流程
这项研究指出,一个AI代理在执行任务时,通常需要完成多个步骤,例如先理解问题、再进行资料检索(RAG)、接着调用工具,甚至执行代码,最后验证结果是否正确。
这些步骤的顺序、是否需要重复,以及在什么情况下触发,都会直接影响最终结果的质量与成本。换句话说,AI代理之间的差异,不只是模型能力,而是这条流程如何被设计。

最佳方案不在两端,而在中间的“半动态”
但目前,大多数团队在流程设计上,仍停留在两种极端。
一种是将流程全部写死,例如固定先查资料、再让模型回答。这种方式虽然稳定,但缺乏弹性,难以应对不同任务场景。另一种则是完全交由AI自行决定下一步,虽然灵活,却容易出现不必要的操作,例如重复查询或过度使用工具,进而导致成本上升,也更难控制错误。
IBM认为,更有效的设计应该介于两者之间,也就是“部分固定、部分动态”的半动态流程。例如,先定义整体任务框架,但允许AI在特定步骤中,自行判断是否需要查资料、是否调用工具,或是否进行额外验证。这样的设计,在维持可控性的同时,也保留了弹性。
在许多AI编程与多代理(multi-agent)系统中,也已出现类似做法,例如让AI先根据规范(spec)规划步骤,再决定是否生成代码或调用工具。
不只是提示词,流程才是影响结果的关键
研究也指出,目前许多团队仍把重心放在提示词(Prompt)优化上,但实际上,影响系统表现的更大因素,是整体流程(Workflow)本身。
这包括AI代理在执行任务时,如何选择与调度工具、如何使用记忆、何时该停下来或再试一次等。换言之,AI表现好不好,不只是模型能力,而是整个系统如何运作。
举例来说,当AI在完成一个任务时,可能会先尝试直接回答;若不确定,再去查资料或调用工具辅助。在这个过程中,它需要持续做出判断:什么时候该用工具、要不要保留前面的信息,以及出错时应该重试还是停止。
而这些判断,其实就是流程设计的核心。
从“看结果”走向“看过程”的优化方式
另一方面,IBM归纳了AI代理的流程优化方法,包括任务指标(Task-specific metrics)、验证机制反馈(Verifier feedback),以及用户偏好(Human preferences)等。这些方法可用于调整AI代理系统行为,进而影响整体流程设计。
其中,验证机制不仅能用来检查结果正确性,还会进一步影响流程本身。例如,在代码生成或问答场景中,当答案未通过验证时,系统可自动触发重新生成、补充检索,或改变推理路径,形成一种持续修正的反馈回路。
此外,IBM特别强调对执行过程(Trace)的分析。通过拆解AI每一步的决策与行为,可以判断错误发生在哪个环节,比如是检索内容不准确、工具选择错误,还是推理过程出现偏差。
更重要的是,这些过程信息不仅能用于调试,还能成为优化指标,用来调整整体流程设计,甚至影响后续决策策略。
这也意味着,AI系统的优化方式,正从单纯地查看最终输出结果,转向分析整个决策过程。
评估AI:不只看有没有答对,还要看怎么做
除了设计方法,IBM还提出了新的评估模式。过去,开发者评估AI系统,多聚焦准确率和响应速度,但这篇研究认为,开发者应进一步评估整体流程。
例如流程是否过于复杂、是否产生过多不必要的工具调用、在不同任务下是否仍能稳定运行,以及Token成本是否随流程设计而放大。也就是说,评估AI代理,不只看有没有答对,还要看“它怎么做到的”。
IBM总结,AI代理的表现,不仅取决于模型本身,也和整个任务流程怎么安排有关,包括是否需要查资料、何时使用工具、怎么利用记忆,以及如何验证等。比起过去着重在单次输出或提示词(Prompt)的调整,最近越来越多研究把重点放在整体执行流程(Execution process),也就是AI在完成任务时,每一步的串联与协作。