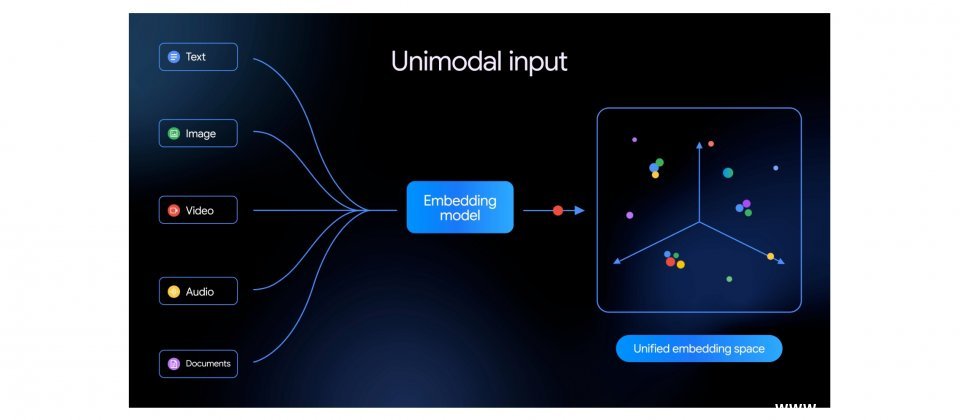
谷歌发布首款原生多模态嵌入模型Gemini Embedding 2,目前通过Gemini API和Vertex AI以公开预览形式提供。相较于谷歌此前以文本为主的嵌入模型,Gemini Embedding 2可将文本、图片、视频、音频与文件映射到同一向量空间,使开发者能够使用同一基础模型完成跨媒介的检索、分类与语义匹配任务。
谷歌在原有嵌入模型能力基础上,进一步拓展至多模态内容处理。官方表示,新模型支持超过100种语言,并可处理图文混合等交错输入,不仅能够识别单一媒介内容,还能理解不同数据类型之间的语义关联。对于企业构建文档检索、音视频资产管理、知识库搜索或检索增强生成(RAG)系统而言,统一的向量空间设计有助于简化原本分散的数据处理流程。
Gemini Embedding 2支持最长8,192个标记(Tokens)的文本输入,每次请求最多可接收6张PNG或JPEG图片,支持最长120秒的MP4或MOV视频,并可直接处理音频而无需先转为文本,同时支持直接嵌入最长6页的PDF文件。谷歌延续了此前模型采用的Matryoshka表示学习训练方式,使嵌入向量即使在降维后仍能保留主要语义信息,官方推荐3,072、1,536与768维作为性能较优的维度选项。
与谷歌之前的文本嵌入模型相比,Gemini Embedding 2的更新不仅是一次版本迭代,更是将嵌入范围从单纯的文本语义表示,扩展至图片、视频、音频与文件的原生多模态表示。谷歌表示,Gemini Embedding 2在文本、图片与视频任务上的表现优于现有主流模型,并新增语音处理能力,进一步扩大了多模态覆盖范围。