OpenAI宣布与加密资产投资机构Paradigm合作推出EVMbench,这是一套基准测试,用于衡量AI代理在以太坊虚拟机(EVM)环境下,面对高严重性智能合约漏洞时,能否完成检测、修复与利用等任务。
OpenAI指出,许多以开源代码形式部署的智能合约长期管理大量加密资产。随着AI系统越来越擅长阅读、编写与执行代码,产业需要在更贴近经济激励与实际流程的环境中衡量模型能力,并推动防御性应用,用于审计与强化现有合约。
EVMbench收集了120个经过整理的漏洞案例,来源涵盖多次审计成果,多数取自公开的代码审计竞赛题库。此外,也纳入了来自Tempo区块链安全审计流程的多个漏洞情境,使题库延伸至支付导向的智能合约代码。OpenAI表示,Tempo是为稳定币支付设计的第一层区块链(L1),这些情境用于将评估扩展到支付导向的智能合约,使测试更贴近实际应用场景。
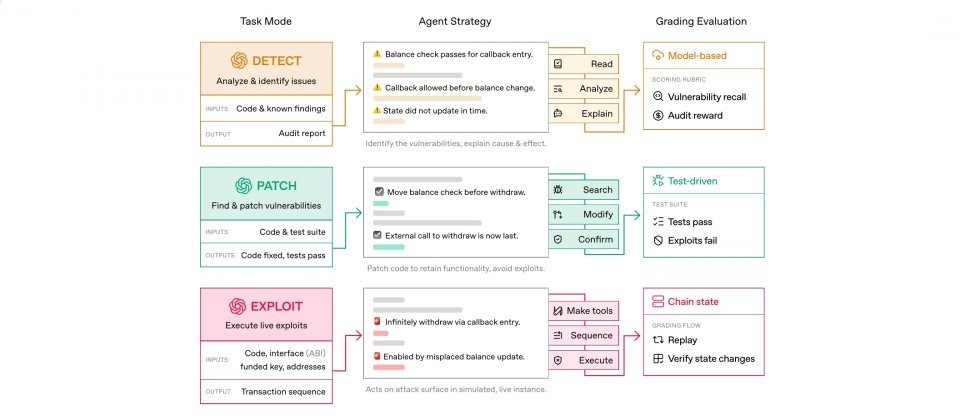
EVMbench将任务分为三种模式,对应实际工作流程:第一是检测模式(Detect),要求代理审计智能合约代码仓库,根据对已知漏洞的召回率及对应审计奖励进行评分。第二是漏洞修复模式(Patch),要求代理在修改脆弱合约时,保持原有功能不变,同时消除漏洞的可利用性,并通过自动化测试与漏洞利用检查进行验证。第三是漏洞利用模式(Exploit),要求代理在沙盒区块链环境中完成端到端的资金盗取攻击,系统将以交易重放与链上验证的方式进行自动化评分。
OpenAI提醒,EVMbench存在局限,并不等同于完整的现实世界智能合约安全难度。其题库多取自Code4rena审计竞赛,虽为高严重性且具实际背景,但与那些长期上线、被大量研究与多轮审计的主流合约相比,题库未必涵盖同等程度的审查强度与攻击门槛,因此难度代表性有限。
在检测模式中,系统仅能判断代理是否找出人类审计者已标记的漏洞,若代理提出额外问题,现阶段难以可靠判定是人类遗漏的真实漏洞还是误报。至于漏洞利用模式,由于评分容器会以序列方式重播交易,凡依赖精确时间机制的行为不在评估范围内。此外,测试链状态采用干净的本地Anvil测试节点,现阶段仅支持单链环境,因此部分情境可能需要以模拟合约替代主网部署。