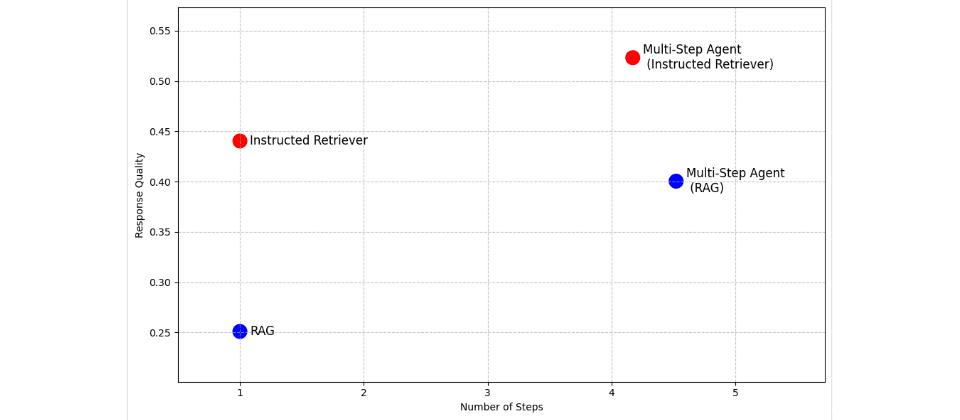
Databricks旗下Mosaic研究团队发布Instructed Retriever研究,主张将系统规范纳入搜索与回复生成流程,使企业搜索代理更能遵循用户指令。研究人员表示,在一套企业问答数据集组合的评估中,Instructed Retriever相比传统RAG的回复质量提升超过70%。
研究人员指出,企业场景常同时要求时间新鲜度、文档类型、数据来源范围与回复长度等限制,但多数RAG方法仅使用用户问题进行单步检索,查询生成后难以保留这些规范,导致后续检索与重排序往往回归文本相似度,容易忽略更精细的意图与数据源差异。
Instructed Retriever的核心是将系统规范作为工作流必须遵守的共同前提,而非仅在初始阶段影响用户问题的改写。研究团队将这些系统规范划分为三类:第一类是用户指令,例如偏好近几年的数据或排除某些品牌;第二类是标注示例,用于界定哪些文档在此任务中属于相关或不相关;第三类是索引描述,即搜索系统实际提供的字段与元数据,使代理能够判断哪些条件可转化为可执行的过滤条件。
由于需要将自然语言的限制转换为可执行查询,团队强调代理必须具备将复杂需求拆解为多个搜索子任务的能力,并能在指令语境下判断相关性,同时将“去年”这类描述转化为时间戳等字段的过滤条件。
在效果验证上,Databricks以半结构化检索基准STaRK为基础,构建了StaRK-Instruct数据集,刻意将常见的企业需求纳入问题中,包括明确要求的条件、明确排除的条件以及偏好较新数据等,以此检验模型能否生成同时包含关键词与字段过滤的结构化查询。
研究人员指出,与直接使用原始问题进行搜索相比,采用指令式查询生成后,在StaRK-Instruct上的召回率提升35%至50%;而在题目大多未特别注明时间新鲜度或排除条件等限制的StaRK-Amazon上,召回率也提升了约10%。
Databricks已在自家Agent Bricks的Knowledge Assistant中引入Instructed Retriever方法,用于构建可附带来源引用的文档型问答聊天机器人。在多步搜索代理评估中,研究团队指出,Knowledge Assistant作为工具相比以RAG作为工具,可带来超过30%的质量提升,平均任务完成时间降低8%。