为什么多奖励强化学习需要一场“信号革命”?
大语言模型早已不再是“答对题”的工具。今天,用户期待的是一台既能精准推理、又懂格式规范、还能控制响应长度、避免有害输出的“智能伙伴”。要实现这种多维度的对齐,单纯靠监督微调(SFT)或单一奖励建模已力不从心。多奖励强化学习(Multi-reward RL)成为行业标配——通过同时优化正确性、安全性、简洁性、格式合规性等多个目标,让模型真正“听懂”人类的复杂偏好。
但问题来了:主流方法GRPO(Group Relative Policy Optimization)在处理多个奖励时,竟在关键环节“失聪”了。
GRPO的致命缺陷:奖励信号被“压缩”成噪音
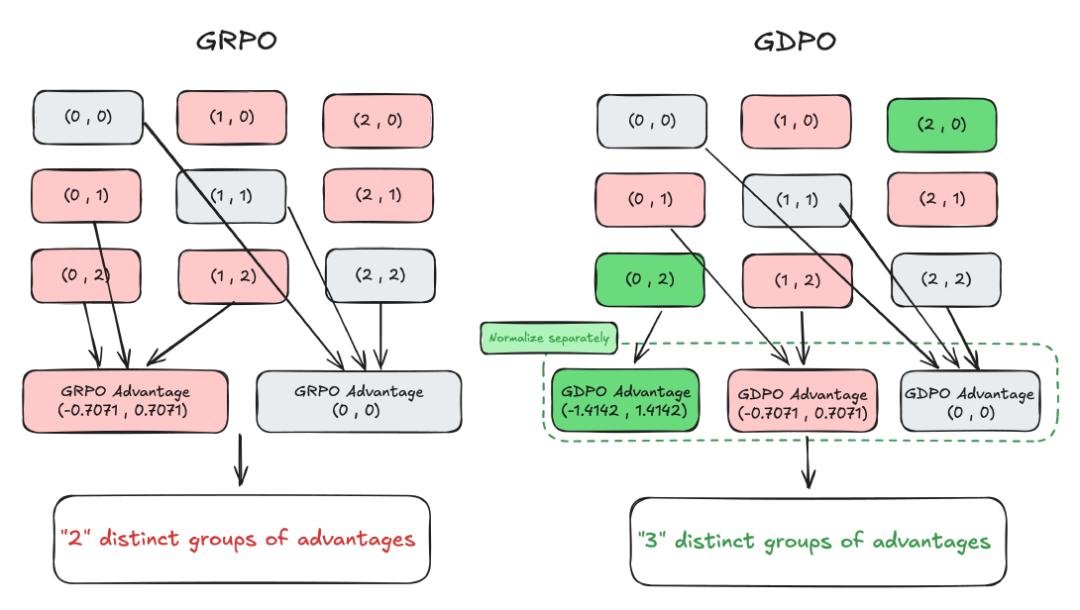
GRPO的做法是把所有奖励加总后做一次全局归一化。听起来合理,实则灾难。举个例子:两个响应,一个奖励组合是(正确性:0, 长度:1),另一个是(正确性:0, 长度:2)。在GRPO中,它们经过归一化后,优势值可能完全相同——这意味着模型根本分不清哪个更好。
这不是理论推测,而是真实训练中的“死亡曲线”。NVIDIA团队在实验中发现:使用GRPO训练约400步后,模型的准确率开始下滑,响应长度约束彻底失效,甚至出现“越训练越乱”的反直觉现象。这不是模型“学坏了”,而是它接收到的信号早已被压缩、扭曲,失去了区分能力。

GDPO:重新设计奖励信号的“显微镜”
NVIDIA团队提出的GDPO(Group reward-Decoupled Normalization Policy Optimization),不是小修小补,而是从底层重构了奖励处理逻辑:
- 先分后合:每个奖励信号独立在组内做归一化,保留原始差异;
- 加权融合:再按重要性加权求和,赋予不同目标合理权重;
- 批次稳定:最后进行批次级优势归一化,避免数值爆炸。
结果是什么?同样是(0,1)和(0,2)这两个组合,GDPO能精准输出-0.7071 和 0.7071 的优势值——差了一倍,模型能清晰感知“长度更优”的价值。而GRPO却把它们压成同一个数字,让模型“无从选择”。
更关键的是,GDPO在奖励数量增加时,仍能保持“独特优势组”的数量呈指数增长。换句话说:奖励越多,GDPO越聪明;GRPO越用越傻。
真实场景碾压:从工具调用到数学竞赛,全面胜出
GDPO不是纸上谈兵。团队在三大高难度任务中,用实打实的数据证明了它的价值:
工具调用:格式正确率暴涨4%
在Qwen2.5系列模型上,GDPO让工具调用准确率提升2%~2.7%,而格式正确率提升超4%——这在API调用场景中意味着90%以上的错误请求被拦截。训练曲线显示,GDPO持续稳定上升,而GRPO在300步后就开始震荡下滑。
数学推理:AIME竞赛准确率+6.7%,长度超标率从85%→0.5%
在DeepSeek-R1和Qwen3-4B等模型上,GDPO在极具挑战性的AIME数学竞赛基准上,准确率提升2.3%~6.7%——相当于从“勉强及格”跃升至“顶尖水平”。更惊人的是,响应长度超标率从**超过85%暴跌至不足0.5%**。这意味着模型不再“答得又长又错”,而是“答得又准又短”,真正实现精度与效率的双赢。
代码生成:通过率+3%,错误率-10%
在APPs、CodeContests和Taco等代码评测集上,GDPO在严格控制响应长度的前提下,将代码通过率提升1%~3%,错误率降低2%~10%。这在工业级代码生成中意味着:你的AI助手不再“写一堆跑不通的伪代码”,而是能直接交付可运行的解决方案。
不只是算法:一场对齐方法论的范式转移
GDPO的价值,远不止于性能提升。它首次系统揭示了:在多奖励对齐中,信号的分辨率,比权重的大小更重要。
过去,研究者总在纠结“正确性该给0.6权重,长度该给0.4”。但GDPO证明:如果你的信号处理机制本身是“模糊滤镜”,再完美的权重也没用。它重新定义了“什么是好的奖励设计”——不是调参,而是构建能保留细微差异的信号通路。
论文还首次提出了一套可复用的条件奖励函数设计框架,为后续研究提供了标准化工具。这就像从“手工调音”进入了“专业录音室”时代。
已开源!立即可用的工业级解决方案
GDPO不是实验室玩具。NVIDIA已将完整代码开源,支持主流RLHF框架:
- Hugging Face TRL:一键替换GRPO,提升现有模型对齐质量
- verl:支持分布式多GPU训练,适配千卡集群
- NeMo-RL:NVIDIA官方集成,企业级部署首选
无论是研究者想复现论文,还是工程师想提升生产模型表现,GDPO都是目前最成熟、最有效的多奖励强化学习方案。你不需要重新训练模型——只需替换训练策略,就能让现有Qwen、DeepSeek、Llama等模型“脱胎换骨”。
未来已来:AI对齐,从“听话”走向“懂人”
当AI能同时兼顾“说对、说短、说准、不说错”,我们离真正的“人类对齐”就更近一步。GDPO证明:真正的智能,不是靠更大的参数,而是靠更精细的信号设计。
如果你还在用GRPO训练你的多目标模型——是时候升级了。因为在这个时代,不是谁的模型更大,而是谁的奖励信号更清晰,谁就能赢得下一轮AI对齐的竞赛。