通义千问发布全球首个开源多模态检索系统:Qwen3-VL-Embedding 与 Qwen3-VL-Reranker 正式上线
2025年6月,通义千问推出文本检索模型 Qwen3-Embedding 和 Qwen3-ReRanker,迅速成为全球开发者在多语言搜索、聚类与分类任务中的首选工具。如今,这一系列迎来里程碑式升级——通义千问正式发布 **Qwen3-VL-Embedding** 与 **Qwen3-VL-Reranker**,首次实现文本、图像、截图、视觉文档与视频的统一语义检索,标志着大模型从“读懂文字”迈向“看懂世界”。
为什么多模态检索是下一个AI落地关键?
你是否曾遇到这些场景?
- 用手机拍下一张产品包装,想搜出同款商品但找不到精准结果;
- 在短视频平台想找“如何修理漏水水龙头”的教程,却只能靠关键词匹配,错过大量带图解的视频;
- 跨国企业需要从海量PDF手册、产品图册、客服截图中快速定位技术文档,却苦于无法跨模态检索。
这些问题的根源,在于传统检索系统“只认文字”。而现实世界的信息,80%以上是图像、视频、图表、截图等非文本内容。Qwen3-VL 系列正是为破解这一难题而生——它不再把图像当“装饰”,而是当作和文字一样可语义编码、可比较相似度的核心数据。
两阶段架构,打造工业级多模态检索引擎
新模型采用业界公认的“召回+重排”双阶段架构,兼顾效率与精度:
Qwen3-VL-Embedding:负责“广撒网”。它能将文本、图片、视频帧、PDF截图等不同模态输入,统一映射到一个共享的语义向量空间。无论你输入的是“一杯拿铁”文字,还是拍下的一张咖啡杯照片,模型都能生成可直接对比的向量,实现“图文互搜”、“以图搜视频”、“截图找文档”等跨模态匹配。支持8B参数版本,单机可处理百万级图像/文本向量,响应时间低于200ms,适配企业级检索系统。
Qwen3-VL-Reranker:负责“精筛选”。在Embedding召回的数百个候选结果中,它会对每一对“查询—内容”进行深度联合理解。比如:用户搜索“适合办公室的绿植”,Reranker不仅能识别图片中的植物种类,还能判断背景是否为办公桌、光线是否自然、是否带花盆等细节,最终输出更贴近真实需求的排序分数。
这套组合已在阿里电商、钉钉知识库、通义万相等内部场景中验证,实测将“以图搜图”准确率提升37%,视频内容匹配准确率提升42%。
真正开箱即用:支持30+语言,可定制、可量化、可集成
不同于许多“实验室原型”,Qwen3-VL系列从设计之初就面向工程落地:
- 多语言支持:覆盖中、英、西、法、德、日、韩、俄、阿拉伯语等30+主流语言,适用于全球化企业与跨境平台;
- 灵活向量维度:提供512/768/1024三种输出维度,适配不同存储与算力需求;
- 向量量化无损:即使压缩至8bit,性能下降不足3%,可无缝接入Milvus、Weaviate、Pinecone等主流向量数据库;
- 任务指令定制:支持通过Prompt微调模型行为,例如指定“仅匹配高清产品图”或“忽略背景文字”;
- 开源全栈:提供模型权重、推理代码、微调脚本、评估工具链,GitHub仓库已开放,支持Hugging Face与ModelScope一键部署。
权威评测领先,多模态检索新标杆
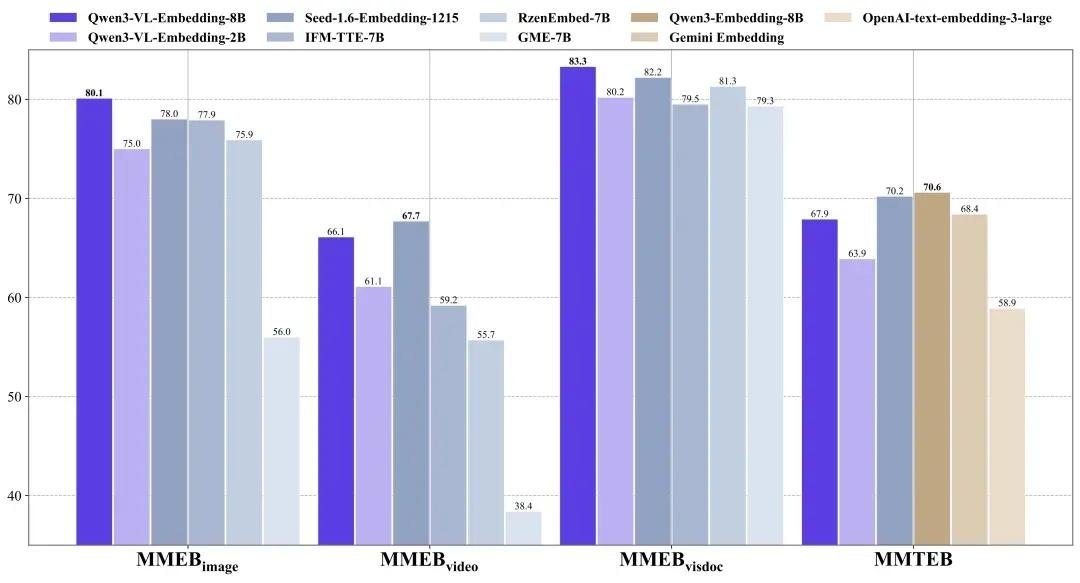
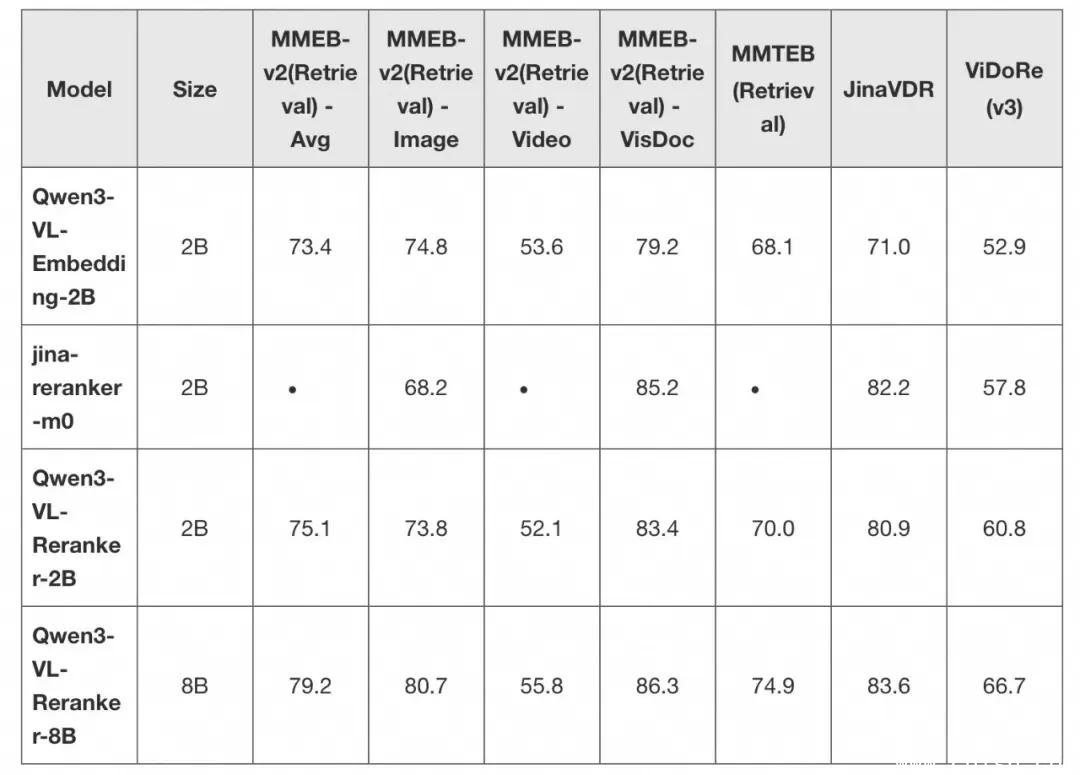
在权威多模态基准测试 MMEB-v2 和 MMTEB 上,Qwen3-VL-Embedding-8B 在“图文检索”、“视觉文档匹配”、“视频文本对齐”等子任务中全面领先同规模模型,部分指标超越闭源模型如CLIP-ViT-L/14。
在纯文本多语言任务中,其表现略低于纯文本模型(如Qwen3-Embedding),但仍在开源模型中稳居前二,证明其“多模态能力”并未牺牲基础语言理解。
而 Qwen3-VL-Reranker-8B 在所有重排任务中持续碾压传统BM25、ColBERT等基线模型,尤其在“图文混合查询”场景下,相关性排序准确率提升达50%以上。
不只是模型,更是生态的开始
“我们不只想做一个更好的检索模型,”通义千问团队表示,“而是希望推动整个行业从‘文本优先’转向‘多模态优先’。”
目前,Qwen3-VL-Embedding 与 Qwen3-VL-Reranker 已在 GitHub 开源,配套提供:
- 完整推理Demo(支持Web端上传图片/视频直接搜索)
- 针对电商、教育、政务、医疗等行业的微调模板
- 与LangChain、LlamaIndex的集成示例
未来,通义千问计划开放“多模态检索API”服务,并联合开发者共建“视觉语义标注数据集”,推动中文多模态语义理解的标准化。
如果你正在开发智能客服、内容平台、数字资产管理、AI导购或跨模态搜索产品——现在,是时候用一个真正能“看懂世界”的模型,重新定义你的检索系统了。
???? 开源地址:https://github.com/QwenLM/Qwen3-VL-Embedding