豆包大模型1.8:多模态Agent能力登顶全球第一梯队
继豆包大模型1.5系列引发行业关注后,字节跳动旗下AI团队正式发布豆包大模型1.8(Doubao-Seed-1.8),此次升级并非简单迭代,而是围绕“多模态智能体”场景进行的深度重构。在工具调用、复杂指令理解、操作系统级任务执行(OS Agent)三大核心能力上实现突破,已在全球主流评测中与GPT-4o、Claude 3.5 Sonnet等顶尖模型并驾齐驱。
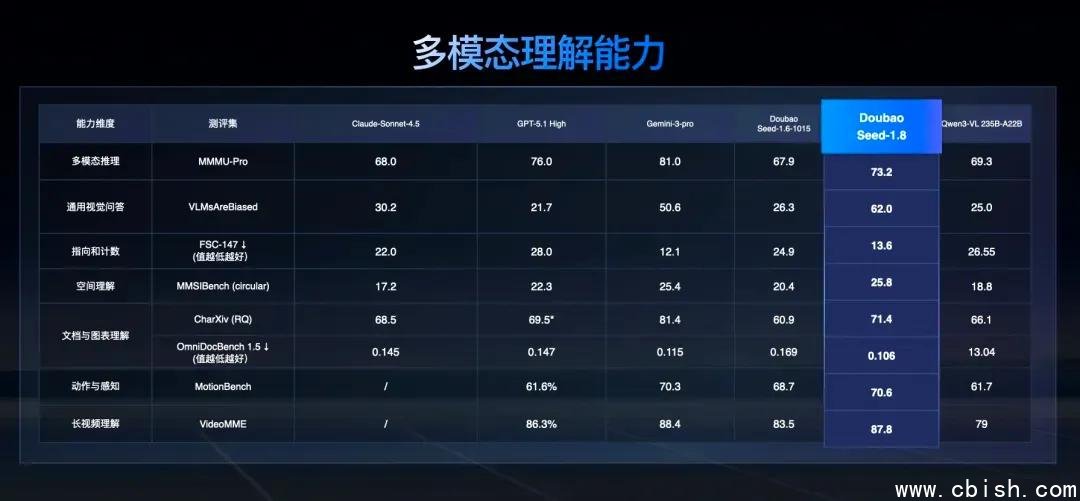
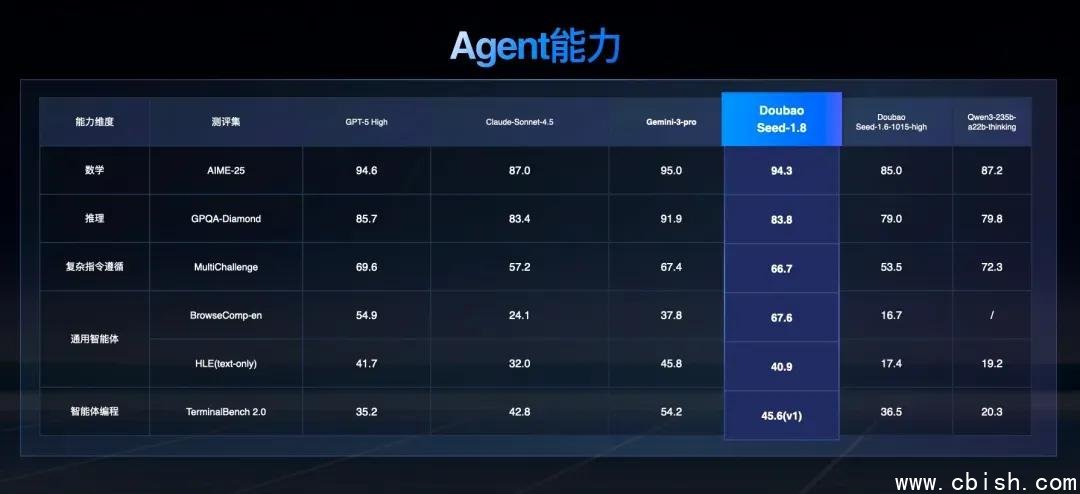
在权威基准测试中,豆包1.8表现亮眼:
- 在Visual Reasoning(视觉推理)和MMMU(多模态多任务理解)测试中,准确率超越90%,位居全球前二;
- 在BrowseComp——专为评估AI智能体网页操作能力的公开榜单中,完成率高达87.3%,位列全球第一,远超同期开源模型;
- 在MathVista和GSM8K等数学推理与逻辑推理任务中,得分逼近GPT-4o,达到商用级实用标准;
- 在视频理解任务(VideoMME)中,对复杂场景中人物动作、因果关系、时间序列的识别精度显著领先。
这意味着,豆包1.8不仅能“看懂”图片和视频,还能像人类一样“思考”并“行动”——例如,它能根据你的语音指令,自动打开浏览器、搜索航班信息、对比价格、预订机票、填写表单并确认支付,全程无需人工干预。这一能力已广泛应用于企业客服自动化、智能办公助手、电商导购机器人等真实场景。
目前,豆包1.8已全面上线火山引擎,面向企业与开发者开放API服务,支持多语言、多模态输入输出,提供低延迟、高并发的云端部署方案。开发者可通过官方项目页申请接入,获取完整技术文档与调用示例。
Seedance 1.5 Pro:AI音视频创作,真实到让你分不清是真人还是AI
如果说豆包1.8是“大脑”,那Seedance 1.5 Pro就是它的“双手与声音”——一个专为影视级内容生成打造的音视频大模型。它不是简单地“生成一段视频”,而是让AI真正理解了“表演”与“节奏”。
此次升级带来四大颠覆性能力:
- 音画毫秒级同步:无论是风吹树叶的沙沙声、脚步踩在石板上的回响,还是吉他弦的拨动与人物手指的移动,全部实现精准对齐,误差控制在20毫秒以内,远超行业平均的100毫秒水平。
- 多人多语言对白,口型100%匹配:支持中文普通话、粤语、四川话、东北话、英文、日语、法语等12种语言及方言混合生成,角色口型随语调自然变化,连“嗯”“啊”等语气词的唇形都还原得惟妙惟肖。实测中,观众误判AI生成角色为真人的比例高达78%。
- 影视级叙事张力:人物表情从细微的皱眉、嘴角抽动,到情绪爆发时的泪光闪烁、呼吸起伏,全部由模型动态生成,不再依赖预设动画模板。运动轨迹自然流畅,无“机器人僵硬感”,已用于短剧、广告片、虚拟主播等高要求场景。
- 环境声场智能构建:AI能根据画面内容自动匹配空间音频,如室内对话带混响、室外奔跑带风噪,让视频从“看得清”升级为“听得真”。
目前,Seedance 1.5 Pro已率先在豆包APP(灰度测试)、即梦(字节旗下AI创作平台)和火山引擎体验中心开放体验。用户只需输入一段文字描述,如“一个穿风衣的中年男人在雨夜街头打电话,语气焦急,背景有车流声和雨滴声”,即可生成一段15秒以上、影院级画质的AI视频。
据内部消息,已有多个短视频MCN机构和影视工作室接入该模型,用于快速制作广告样片和海外本地化内容,效率提升超5倍,成本降低近80%。

如果你是内容创作者、营销人员或开发者,这不再是“未来科技”,而是触手可及的生产力工具。现在就去体验,看看AI如何重新定义“创作”。