Kimi 新模型登顶长上下文评测,颠覆传统认知
近日,知名长上下文评测平台 Context Arena 更新榜单,两款来自月之暗面(Kimi)的模型——kimi-linear-48b-a3b-instruct(简称 kimi-linear-48b)与 kimi-k2(Thinking) 正式加入评估体系,引发业界广泛关注。尤其令人意外的是,kimi-linear-48b 在 512k 乃至 1M token 的超长上下文任务中,表现全面反超谷歌 Gemini 3.0 Pro Thinking,成为当前长文本处理领域的一匹“黑马”。
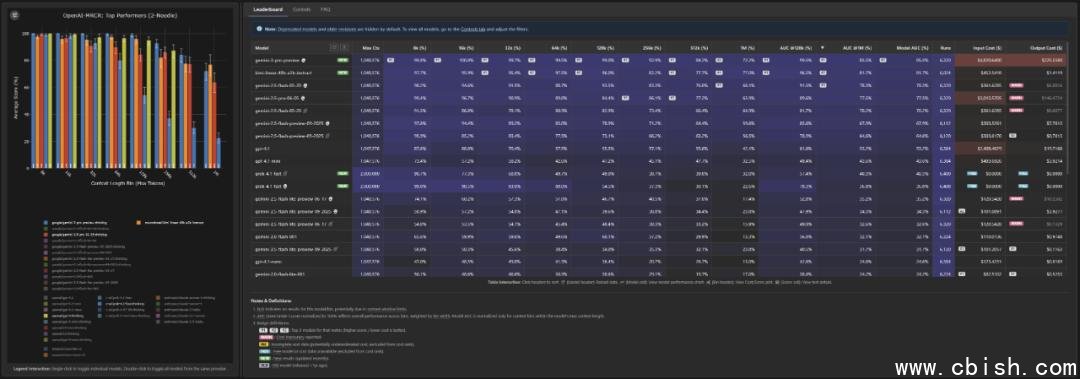
反常表现:短文本平庸,长文本封神
与主流大模型“越长越弱”的趋势不同,kimi-linear-48b 的性能曲线呈现出罕见的“逆向优势”:在 256k 以下的常规上下文任务中,它的表现甚至落后于 GPT-4o 和 Gemini 3,尤其在高难度的 8-needle 测试中,准确率明显偏低。但在 512k、1M 这类极限长度场景下,它却展现出惊人的稳定性。
根据 Context Arena 研究员 Dillon Uzar 的分析,kimi-linear-48b 采用了与 Transformer 架构截然不同的“线性注意力扩展”技术路线,避免了传统模型在超长序列中因注意力计算复杂度爆炸而导致的性能断崖式下跌。这一设计让它在处理百万级上下文时,表现曲线异常平缓,几乎无衰减。
关键数据对比:1M 上下文,它赢了
以下是 kimi-linear-48b 与 Gemini 3.0 Pro 在多组 Needle-in-a-Haystack 测试中的核心数据对比(括号内为 Gemini 3.0 Pro 数据):
2-needle(128k / 1M)
AUC:96.5%(99.5%) / 81.7%(85.5%)
Pointwise:96.0%(99.0%) / 77.0%(72.2%)
4-needle(128k / 1M)
AUC:85.5%(85.8%) / 62.7%(57.3%)
Pointwise:83.7%(80.8%) / 51.5%(34.3%)
8-needle(128k / 1M)
AUC:54.9%(73.0%) / 43.8%(39.0%)
Pointwise:49.0%(54.2%) / 35.3%(24.5%)
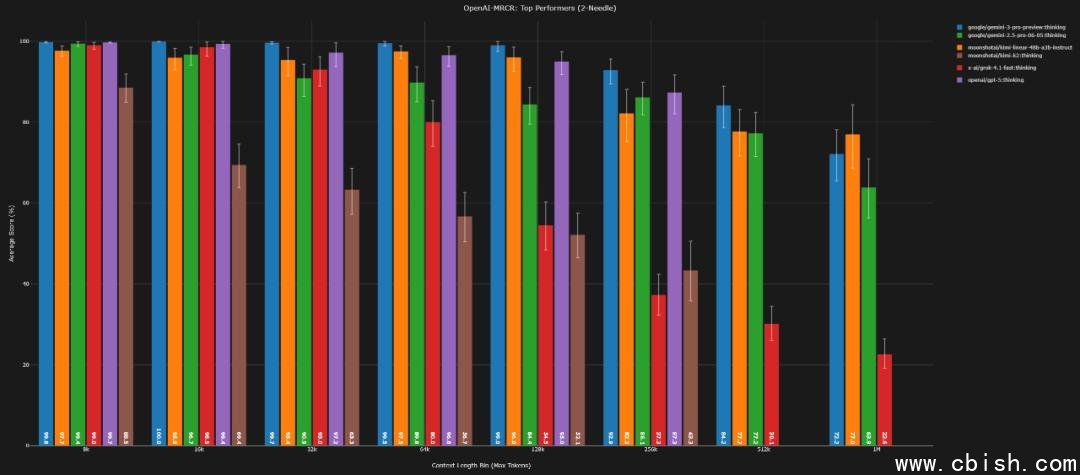
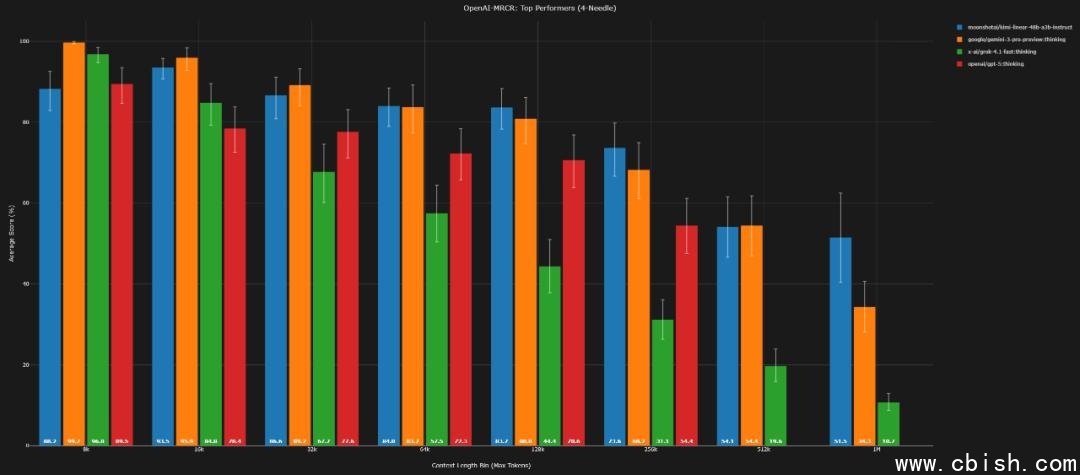
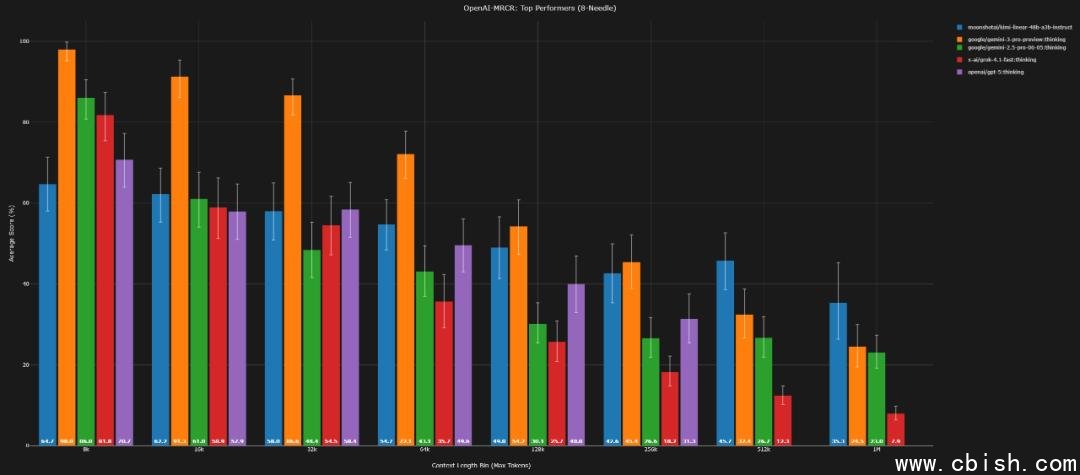
从数据可见,在 1M 上下文下,kimi-linear-48b 在 4-needle 和 8-needle 任务中,AUC 和 Pointwise 准确率均实现对 Gemini 3 的反超,尤其在 8-needle 的 Pointwise 任务中,差距拉大至 10.8 个百分点,这意味着它在极端复杂信息检索中,能更稳定地定位关键内容。
代价与挑战:显存吃紧,效率待优化
但优势背后,也有现实瓶颈。由于其架构未采用主流的 KV 缓存压缩或分块注意力机制,kimi-linear-48b 的 token 利用率较低,同等条件下更容易触发显存溢出。在 1M token 的完整测试中,仅约 60% 的运行能成功完成,远低于 GPT-4o 和 Claude 3.5 的 90%+ 成功率。
此外,在 128k 以上长度的简单任务(如 2-needle、4-needle)中,它反而出现小幅性能下滑,说明其优化方向并非“全面增强”,而是专注“极限拉伸”。这使其更适合对上下文长度有硬性要求的场景,如法律合同分析、科研论文综述、超长对话历史回溯等,而非日常对话或短文本问答。
kimi-k2(Thinking)表现平平,仍处探索阶段
相比之下,kimi-k2(Thinking)版本虽引入了类似“思维链”的推理机制,但在 Context Arena 榜单中表现相对保守。在 128k 的 2-needle AUC 测试中仅排名第 22,且在约 262k 长度处即触及性能天花板,未能参与更高难度测试。这表明其“思考”能力尚未有效转化为长上下文理解的增益,仍处于技术验证阶段。
行业意义:长文本赛道迎来“非主流”破局者
kimi-linear-48b 的出现,打破了“越大的模型、越复杂的架构,长文本表现越好”的固有认知。它证明了一种轻量、线性扩展的架构,也能在超长上下文任务中实现“以柔克刚”的效果,为行业提供了全新的技术路径参考。
有业内人士指出,若该模型能进一步优化显存效率,未来有望在金融风控、医疗病历分析、政府公文处理等对“长文本精准检索”有刚需的领域落地。而其“不求全能,但求极致”的设计哲学,也正呼应了当前 AI 从“通用大模型”向“场景专用模型”演进的趋势。
目前,kimi-linear-48b 尚未开放公众 API,但其测试结果已通过 Context Arena 公开,成为研究者们分析长上下文模型设计的又一重要样本。未来,是否会有更多“非 Transformer”架构涌现?这场关于“长度 vs 效率”的竞赛,才刚刚开始。