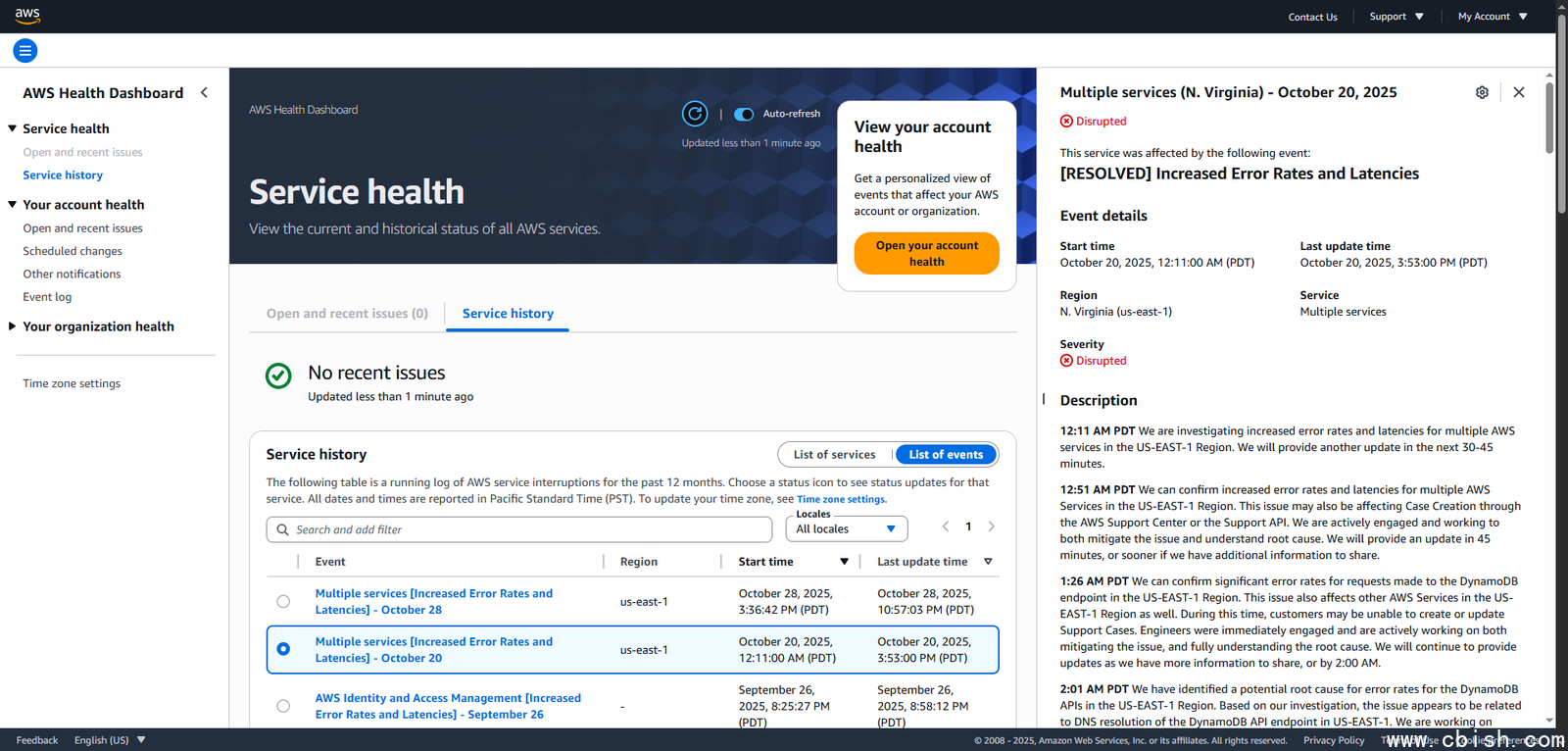
上个月,公有云服务商AWS美国东部第一区(US-EAST-1,弗吉尼亚北部)的数据中心,因DynamoDB服务的DNS自动管理系统存在潜在缺陷,导致该区域的DynamoDB端点(dynamodb.us-east-1.amazonaws.com)域名解析失败。由于自动化修复机制未能有效介入,进而影响了依赖该数据库服务的其他云服务。AWS已在10月20日的AWS Health Dashboard仪表盘,以及10月23日发布的调查报告摘要中披露了事件经过,但公众仍关注此次大规模中断所引发的连锁影响究竟有多广泛。
 ??
??
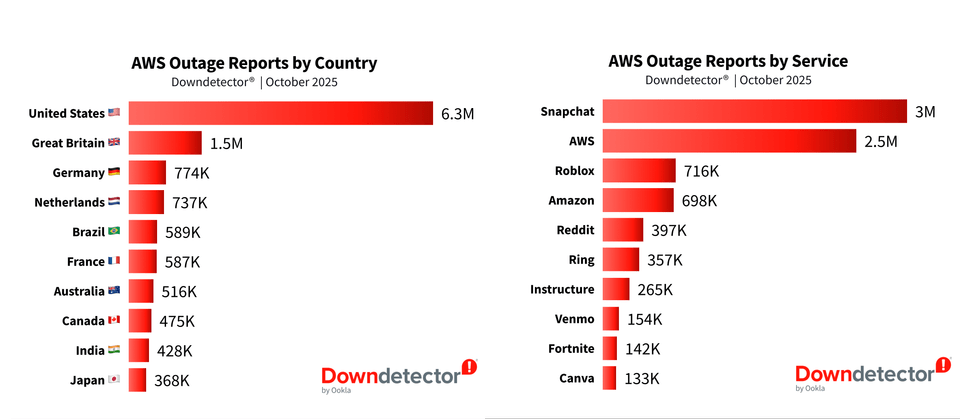
尽管当周多家主流媒体相继报道了此次事故,提及数千家企业受影响,但这一数字的来源尚不明确。一家提供Speedtest与Downdetector服务的网络测速与网络质量分析公司Ookla,从用户反馈角度提供了另一种观察视角,或可作为影响范围的具体佐证。根据Downdetector在10月22日发布的统计报告,其记录了来自1700万份用户上报的故障信息,显示全球超过60个国家、3500余家公司受到波及,是Downdetector有记录以来规模最大的互联网中断事件之一。

受影响最严重的五个地区分别为:美国(超630万次上报)、英国(超150万次)、德国(77.4万次)、荷兰(73.7万次)、巴西(58.9万次)。
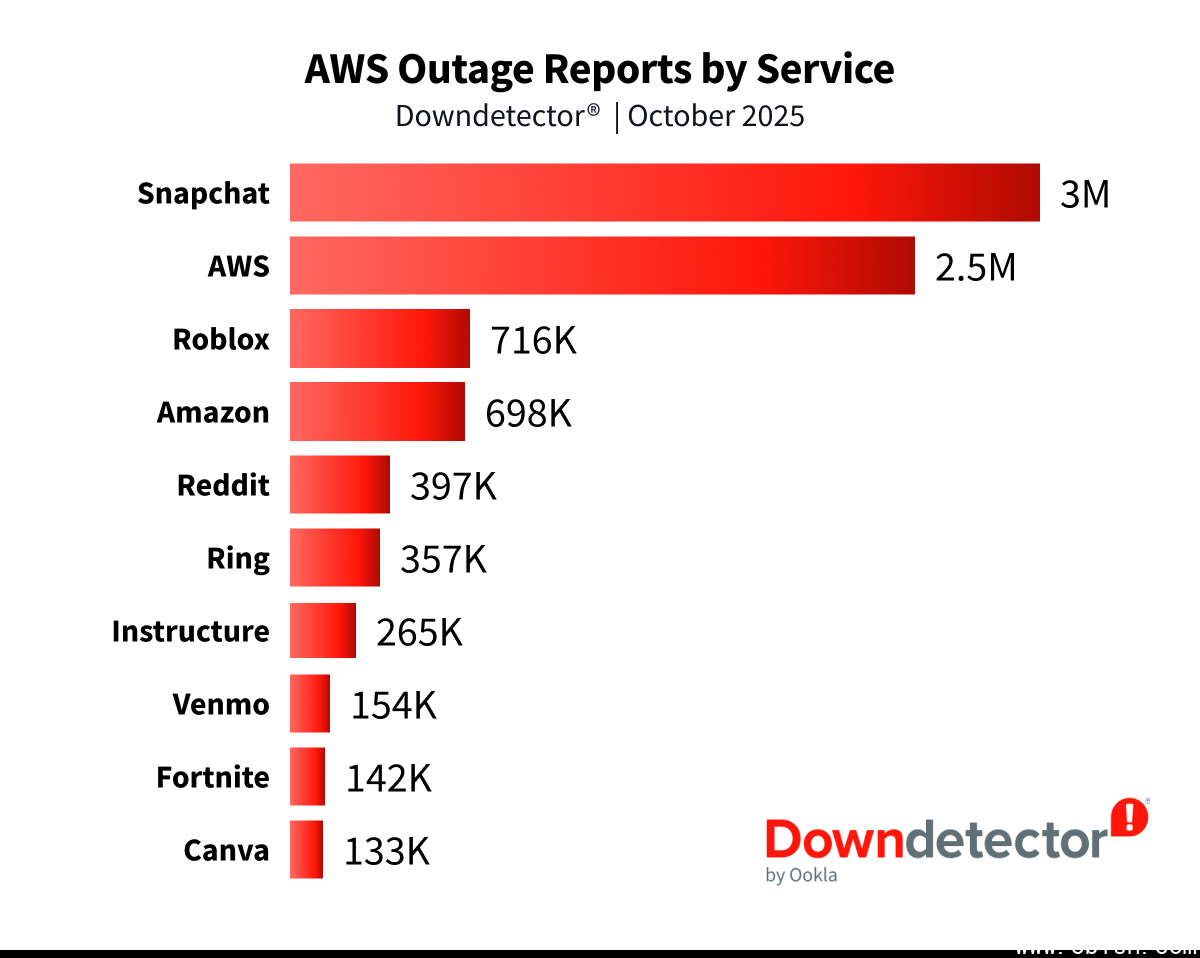
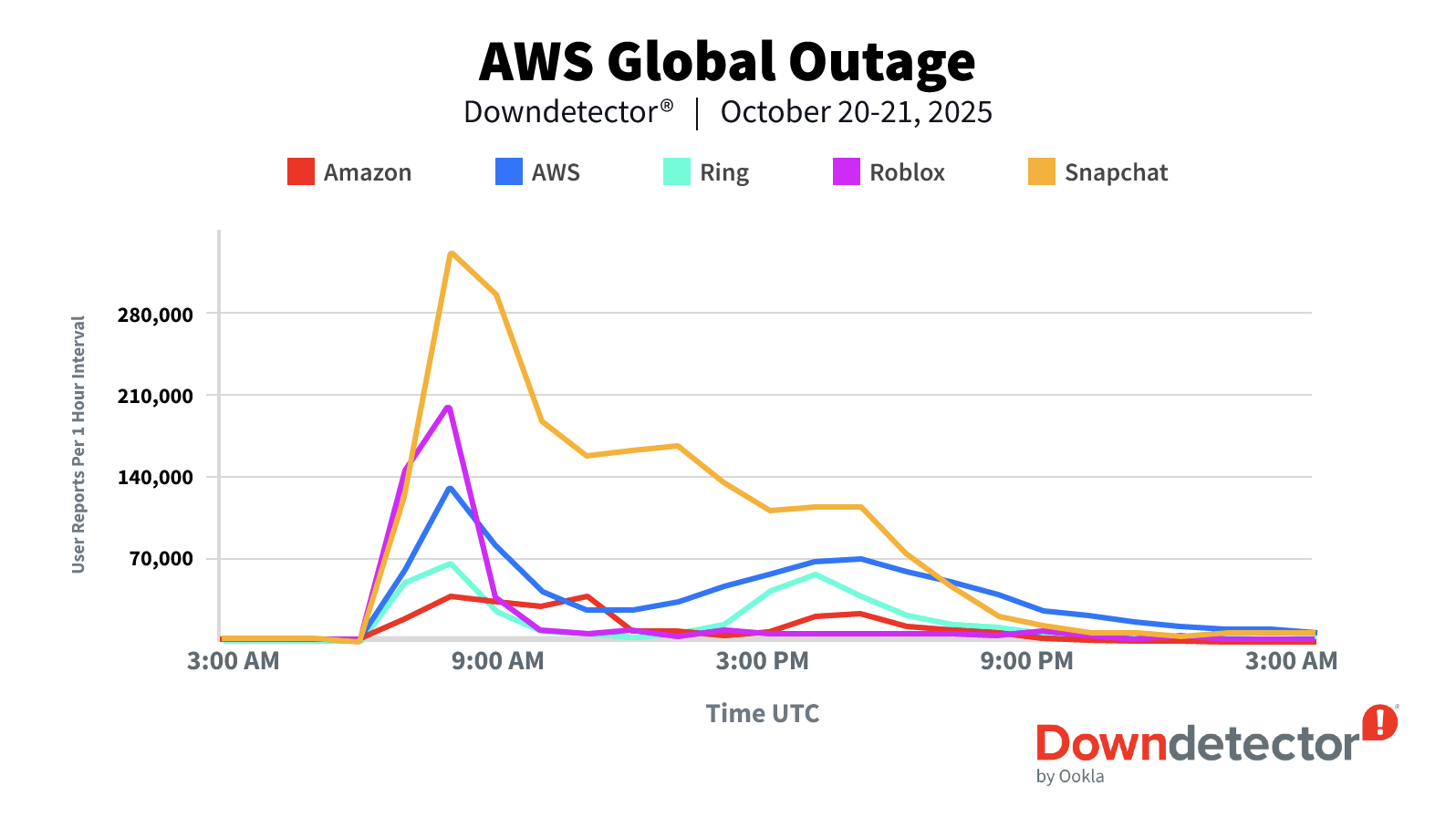
按上报数量排名前十的服务商依次为:即时通讯与社交应用Snapchat(约300万次)、公有云服务AWS(约250万次)、游戏平台Roblox(约71.6万次)、亚马逊零售业务(约69.8万次)、社交论坛Reddit(约39.7万次)、物联网门铃服务Ring(约35.7万次)、教育科技SaaS平台Instructure(约26.5万次)、移动支付服务Venmo(约15.4万次)、多人在线游戏《堡垒之夜》(Fortnite,约14.2万次)、多媒体创作SaaS工具Canva(约13.3万次)。整体来看,此次事故广泛波及多个领域,包括社交与游戏(Snapchat、Fortnite、Roblox)、金融 banking(英国劳埃德银行与汇丰银行)、公共服务(英国税务海关总署)、智能家居(Ring与Alexa)、教育与办公工具(Instructure与Zoom)等。
受AWS大规模中断影响,Downdetector的记录显示,各地服务中断的高峰与低谷受时区差异影响明显。欧洲地区的上报量率先激增,因为当时已是当地10月20日上午,办公场景已全面启动;第二波高峰出现在北美地区10月20日上午。
Ookla特别梳理了三个关键时间节点:
首先,在世界协调时间10月20日6时49分,出现首批用户上报,与AWS官方状态信号同步;6时56分,Downdetector记录到连接US-EAST-1区域的服务出现急剧飙升,故障发生两小时后,累计收到超过400万次服务中断报告。
其次,在9时24分,AWS确认故障主因为US-EAST-1区域DynamoDB端点的DNS解析问题,并宣布已开始缓解。
10月20日之后,依赖AWS的各类服务以不同速度逐步恢复,过程中系统持续通过重试、排队执行、缓存清除等方式进行修复。随着更多用户上线,Downdetector一度监测到美国地区的中断上报数量突破600万次。
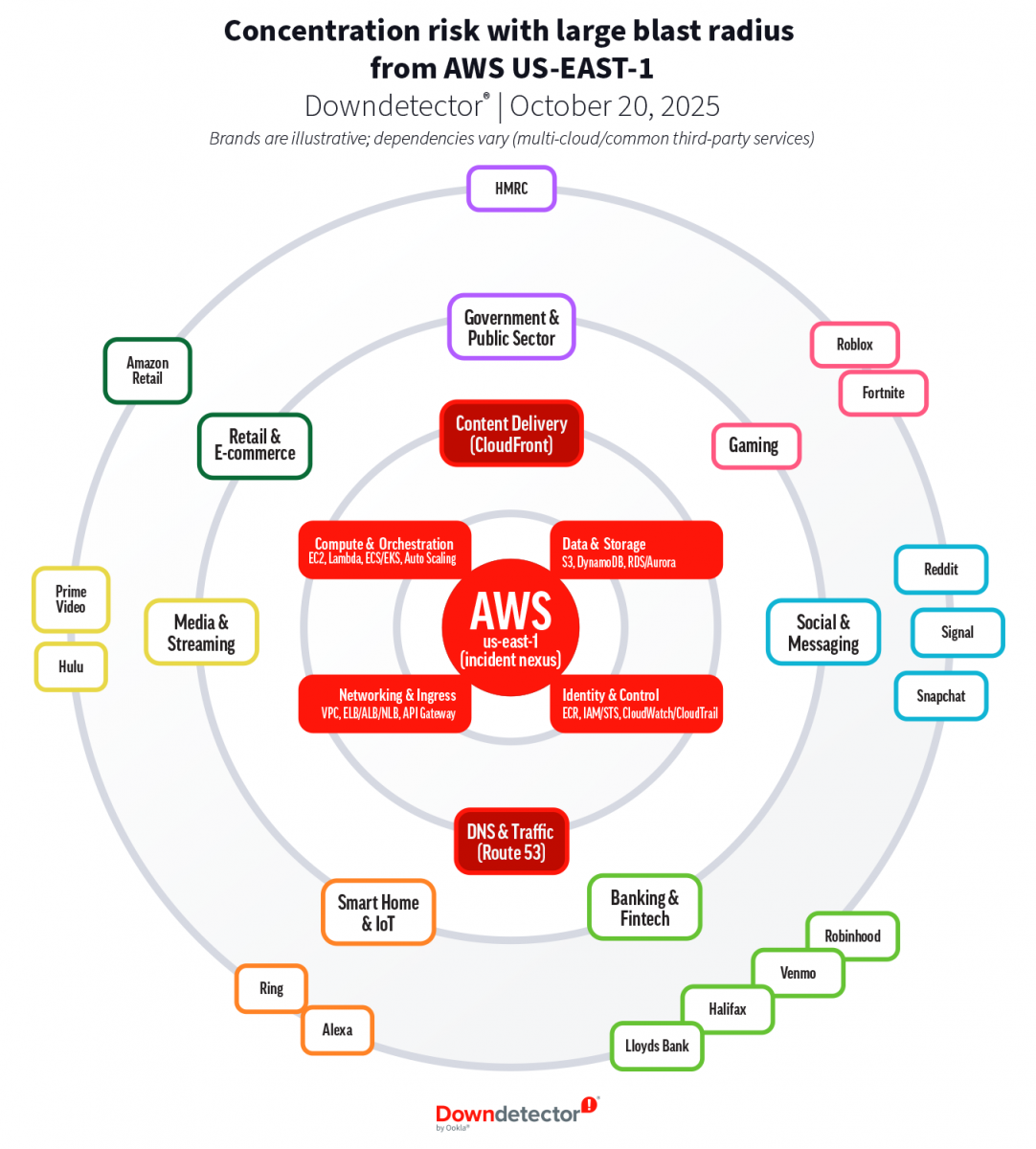
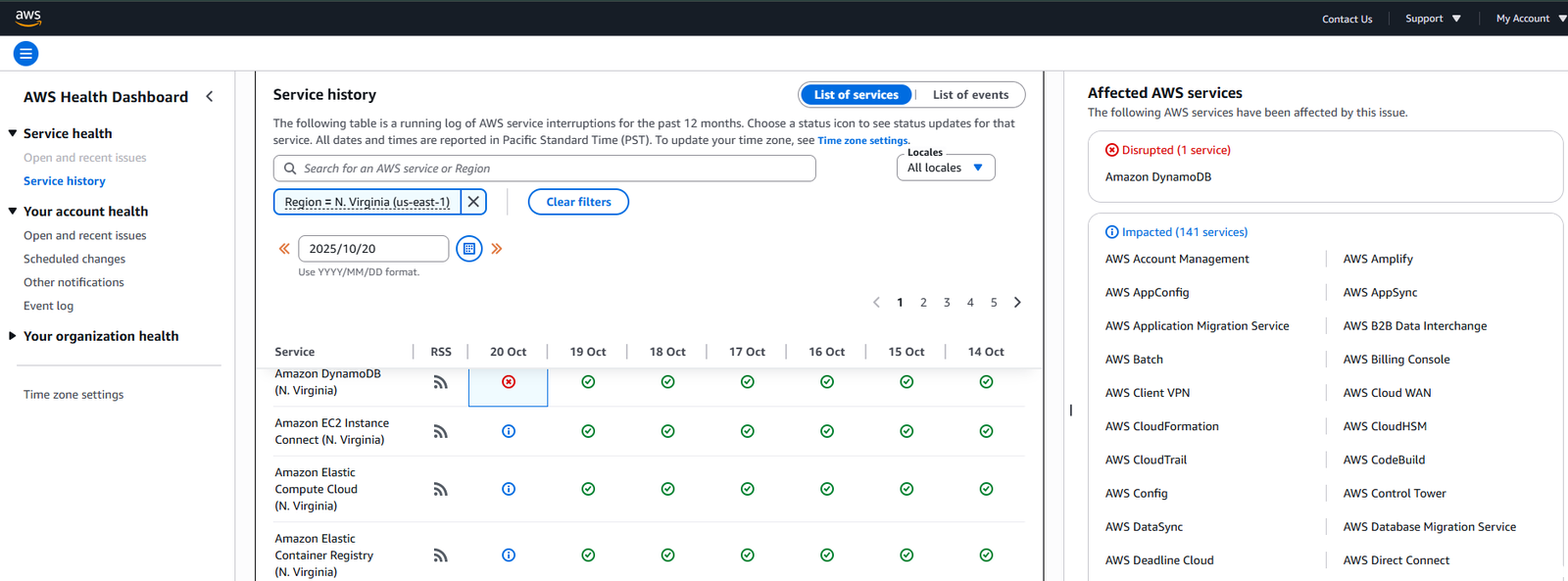
为何US-EAST-1的故障会波及全球60多个国家的用户?Ookla分析认为,根源在于“区域集中”与“服务高度耦合”。AWS拥有大量支撑全球业务的核心技术基础设施,其流量路由普遍经过该区域;而当前多数应用系统依赖多种全托管云服务(如存储、队列、无服务器架构等),一旦DNS无法解析DynamoDB等关键API端点,便可能通过多层API调用链引发连锁故障,导致即使不直接使用AWS的用户应用也出现明显异常,这正是Snapchat、Roblox、Signal、Ring、HMRC等服务瘫痪的根本原因。
另一加剧事故复杂性的因素是身份认证系统。DynamoDB故障同时冲击了AWS的身份与访问管理服务(IAM),导致部分运维团队在事故初期无法登录AWS管理控制台,无法调整配置、转移流量或重启服务,从而延误了应急响应。即便核心系统后期恢复,由于大量重试请求、超时积压和消息堆积(backlogs)尚未清理,AWS运维团队不得不限制重启频率,以避免对后端系统造成二次冲击,因此系统恢复过程缓慢。只有当供应商端的底层服务彻底稳定后,终端用户才能逐步感知到服务恢复正常。
Downdetector的上报数据也印证了这一模式:欧洲地区在10月20日下午率先恢复,随后才是北美地区。