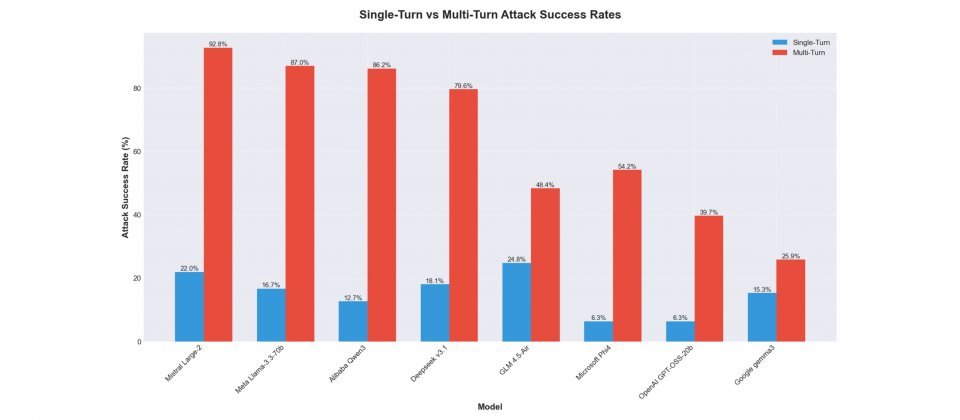
Cisco AI防御研究人员指出,多轮提示攻击(Multi-Turn Attack)正成为开源权重大型语言模型的主要弱点。在针对8款开源权重模型的黑箱测试中,研究团队发现,模型在多轮对话中更容易被诱导生成违规内容,攻击成功率最高达92.78%,最低也有25.86%,整体成功率约为单轮攻击的2至10倍。
研究通过AI Validation平台进行自动化测试,涵盖阿里巴巴的Qwen3-32B、Meta的Llama 3.3-70B-Instruct、Mistral Large-2、DeepSeek v3.1、Google的Gemma-3-1B-IT、微软Phi-4、OpenAI的GPT-OSS-20b,以及智谱AI的GLM-4.5-Air等模型。测试全程采用黑箱方式,研究人员未事先掌握模型内部架构或防护机制,并依据MITRE ATLAS与OWASP的AI安全分类标准评估模型的防御能力。
结果显示,几乎所有模型在多轮对话中均出现防护失效现象。以Mistral Large-2为例,多轮攻击成功率达92.78%;而Google Gemma-3-1B-IT相对稳定,仅为25.86%。这些结果凸显模型在单轮与多轮防护能力之间存在显著差距。以Qwen3-32B为例,差距高达73.48%,表明模型在长对话场景下的防御能力明显下降。
研究人员指出,攻击者常通过语境误导、渐进升级、信息拆解重组、角色扮演、拒绝改写或转向等策略,逐步削弱模型的安全约束。其中,信息拆解重组与语境误导最具威胁性,可使模型在无意识状态下生成违规或敏感内容。此类攻击在企业应用场景中可能造成实际风险,例如客服系统被诱导泄露用户数据,或决策辅助工具输出不当建议,影响业务正常运行。
Cisco分析认为,模型的训练导向与对齐策略是影响安全缺口的主要因素之一。强调能力开放与性能表现的模型,如Mistral与Meta Llama系列,在多轮测试中往往暴露较大漏洞;而注重安全对齐与输出稳定性的模型,如Google Gemma与OpenAI GPT-OSS-20b,虽然整体能力相对保守,但能更一致地维持防护效果。这也说明,开源权重的高自由度虽推动技术创新,却同时放大了安全风险。
研究人员建议,在部署前应进行全面的安全审计,并将多轮对话测试纳入评估标准,同时结合对抗训练、上下文感知防护、实时监测与红队演练等措施,降低越狱攻击风险。报告最后指出,开源权重仍是推动人工智能生态发展的重要基础,但若缺乏相应的安全工程与治理机制,多轮提示攻击将持续成为开源模型的最大隐患。