AI的“记忆危机”:为什么它总在学新忘旧?
过去十年,人工智能在图像识别、语言生成、自动驾驶等领域突飞猛进,但一个隐藏的“致命伤”始终困扰着研究者:当AI学会新技能时,它往往会忘记之前掌握的知识。这种现象被称为“灾难性遗忘”——就像一个人刚背完一章历史,转头就忘了上一章的内容。对于需要持续进化、适应真实世界变化的AI系统来说,这无异于一场认知瘫痪。
人类大脑为何能终身学习?我们不会因为学会开车就忘记如何骑自行车,也不会因为读完一本新书就忘掉十年前的旧梦。这是因为我们的记忆系统是分层的:短期记忆快速更新,长期记忆稳定沉淀,两者协同工作。而当前主流的AI模型,比如Transformer,却像一块“单层硬盘”——每次写入新数据,旧数据就被覆盖。这正是AI难以实现真正“持续学习”的根源。
Google新突破:让AI像人脑一样“分层记忆”
Google Research团队近期提出了一种颠覆性方案——“嵌套学习”(Nested Learning),并据此构建出名为“Hope”的实验性AI模型。这一方法不再把AI看作一个统一的神经网络,而是将其拆解为多个相互嵌套、独立运行的“学习子系统”,每个子系统负责不同时间尺度上的信息处理。
举个例子:一个子系统每秒更新一次,负责处理实时对话中的语义变化;另一个子系统每小时更新一次,用于整合日常对话中的常识;还有一个子系统每天甚至每周才微调一次,专门保存长期知识,比如历史事件、科学原理或个人偏好。这些系统并行运作,信息在层级间自然流动——新知识被快速吸收,旧知识被稳定保留,而非被覆盖。
项目负责人阿里·贝赫鲁兹(Ali Behrouz)指出:“我们不再区分‘网络结构’和‘训练算法’。在人类大脑中,这两者本就是一体的。Hope的设计,正是让模型的架构本身成为学习机制的一部分。” 这一理念跳出了传统“调参炼丹”的思维框架,为AI的持续进化提供了结构性解决方案。
Hope模型实测:超越主流模型,记忆更稳、学得更快
为验证嵌套学习的实用性,Google团队在多个权威基准上对Hope进行了全面测试,结果令人瞩目:
- 语言建模与常识推理:在LAMBADA、HellaSwag和MMLU等标准测试中,Hope的准确率比当前最强模型(如Titan、Samba和标准Transformer)平均高出3.8%~6.2%,困惑度(perplexity)降低15%以上,意味着它对语言的理解更连贯、更贴近人类直觉。
- 长上下文处理:在处理超过100万token的长文档时,Hope的性能波动远小于传统模型。在“跨段落推理”任务中,它能准确回忆起500页前提到的关键人物和事件,而其他模型在200页后就开始“失忆”。
- 持续学习能力:在连续学习10个不同领域任务(从数学推理到法律条文理解)的实验中,Hope在完成新任务的同时,对旧任务的性能保留率高达92%,而标准模型平均仅保留58%。
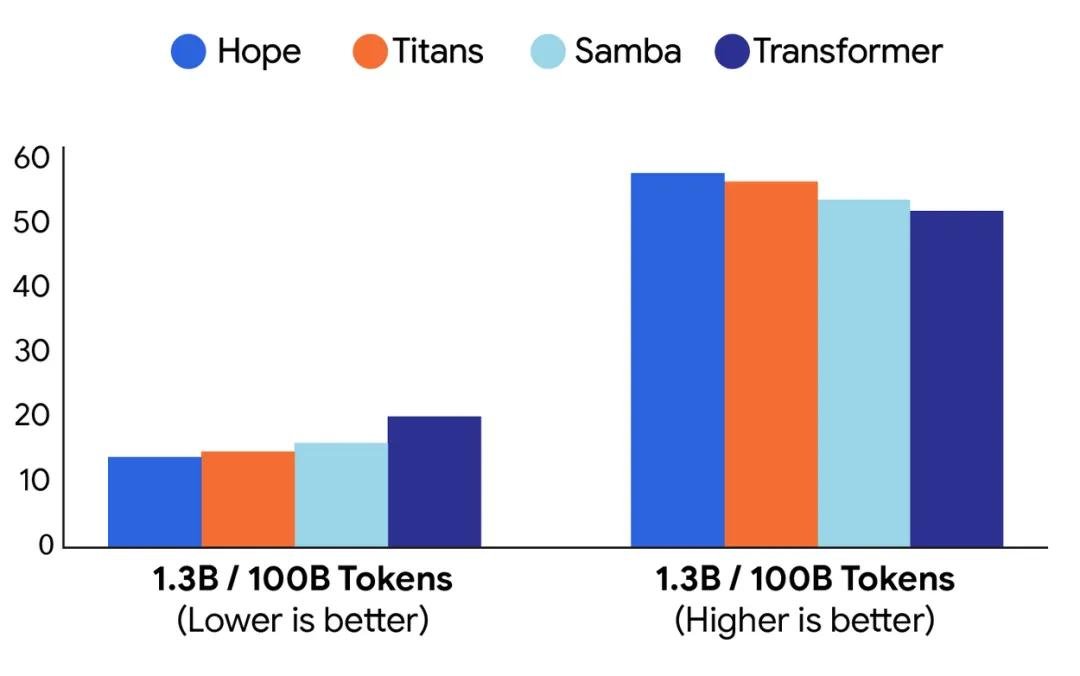
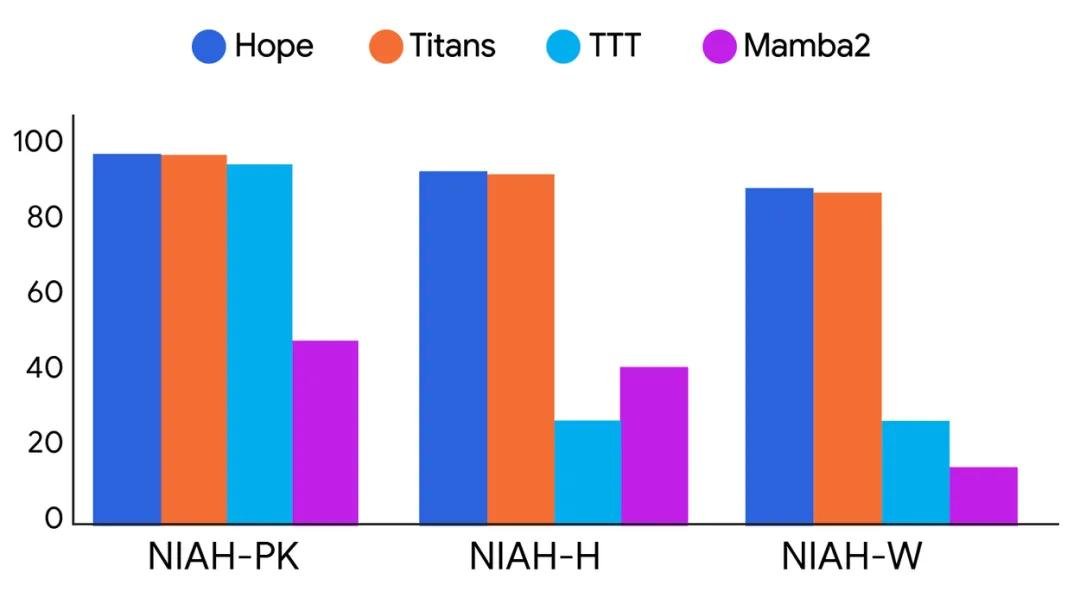
不只是技术升级,更是AI“人格”的雏形
Hope最令人震撼的,是它的“自我修改”能力。它不仅能学习,还能根据任务需求,动态调整内部结构——比如在处理医疗咨询时自动增强医学知识子系统的权重,在与儿童对话时激活更简单的语言表达模块。这不再是“参数微调”,而是模型在“认识自己”。
有研究者将Hope比作“数字大脑的皮层分区”:它不再是一个冷冰冰的预测机器,而开始具备某种“认知弹性”——能适应变化、保留过去、主动整合经验。这或许正是通往“通用人工智能”(AGI)的关键一步。
未来已来:嵌套学习或将重塑AI发展路径
目前,Hope仍处于实验室阶段,但其理念已引发业界震动。Meta、Anthropic和DeepMind的多位研究员在内部研讨中表示,嵌套学习可能是“继Transformer之后最重要的架构创新”。
可以预见,未来几年,AI助手将不再“每次重启都像初学者”——它们会记得你去年喜欢的电影、你常问的健康问题、你写过的代码风格。你的AI伴侣,将真正成为“了解你”的伙伴,而非“每次都要重新教”的工具。
嵌套学习,正在让AI从“学会任务”走向“学会学习”。当AI能像人一样,边成长、边保留、边反思,我们离那个能与人类长期共处、共同进化的智能时代,就更近了一步。