Meta发布专攻代码生成的326亿参数世界模型CWM
Meta研究世界模型对代码生成能力的提升,发布开放权重326亿参数(32.6B)模型Code World Model(CWM),专门针对代码生成场景。与仅以静态代码进行训练的方法不同,CWM在预训练与强化学习之间加入中期训练(Mid-training),引入大量来自Python解释器与容器化环境的观察、动作轨迹,使模型不仅能学会语法与范式,还能从实际执行过程中推断状态变化,显著提升错误定位与修复、长上下文程序分析以及多轮次系统交互的效率与稳定性。
CWM的训练目标是在可验证场景中增强推理与规划能力。其中,在中期训练阶段特别引入两类可观测的数据来源:其一是大量Python程序在容器中的内存追踪数据,其二是多轮次代理与计算环境的交互轨迹。随后通过多任务、多轮次的可验证强化学习(RL)进行后训练,使模型能够逐步模拟程序执行与错误修复过程,贴近开发者日常的运行、观察、修正流程。
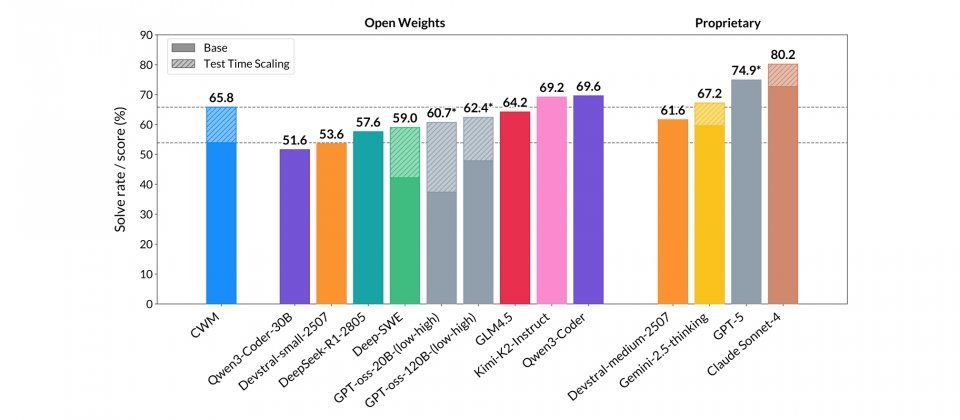
从基准测试成绩来看,CWM在SWE-bench Verified上,未启用测试时扩展机制(Test-time Scaling, TTS)的单次作答正确率为53.9%,启用后提升至65.8%,显示在代理式工作流与TTS下有明显的性能提升。在LiveCodeBench v5/v6上分别达到68.6/63.5,表现处于开源模型前列水平,与Qwen3-Coder-32B、Devstral-1.1-24B互有领先。在数学任务中,Math-500得分为96.6%,属于顶尖水平,但在AIME-24/25上为76.0/68.2,落后于针对竞赛题优化的Magistral与Qwen3系列模型。
整体来看,CWM并非全能第一,但在程序理解、错误修复与容器化执行等工程导向场景中表现突出。若目标是长上下文程序分析、可验证修复与系统交互,CWM的世界模型训练与TTS设计更具实用价值。
CWM的价值在于提供一个能观察、推理、修正的实验平台,便于分析世界模型对代码生成与规划的影响,并测试不同训练阶段对最终行为的贡献。研究人员可从发布的各阶段权重入手,评估中期训练与强化学习在可验证任务中的效果,并观察长上下文与多轮次交互下的稳定性与可复现性。