OpenAI发布GDPval评估标准,衡量AI在真实经济任务中的表现
OpenAI本周四(9月25日)发布了GDPval评估标准,用于衡量AI模型在具有经济价值的真实世界任务中的表现。该标准涵盖了对美国国内生产总值(Gross Domestic Product,GDP)贡献最大的9个行业、44种职业以及1,320项具体任务。首次评测结果显示,整体表现最佳的是Anthropic的Claude Opus 4.1。
OpenAI表示,GDPval旨在提供一套能够反映AI模型真实经济影响的衡量方法,弥补传统基准测试过于侧重学术题目或编程竞赛的局限。通过评估具体的工作成果,如法律报告、工程设计、医疗护理方案等,GDPval更贴近专业人士的日常工作,能够更准确地衡量模型在实际生产力方面的潜力。
首版GDPval选取了对美国GDP贡献超过5%的九大行业,包括房地产、政府、制造业、专业技术服务、医疗保健、金融保险、零售、批发以及信息产业,并在每个行业中挑选了44个以知识工作为主的职业。每个职业设定了30项任务,总计1,320项,均由平均拥有14年经验的专业人士撰写和审核,确保任务的真实性与代表性。OpenAI从中选出220项任务组成黄金评估集,作为各AI模型比较评估的标准测试集。
在评估过程中,OpenAI邀请了来自各职业领域的专业评审进行盲测,对比AI模型与人类专家的产出结果,并依据质量、美观性、准确性等标准进行评分。同时,OpenAI还开发了一套可模拟专家打分的自动评分系统,未来将通过evals.openai.com向研究社区开放使用。
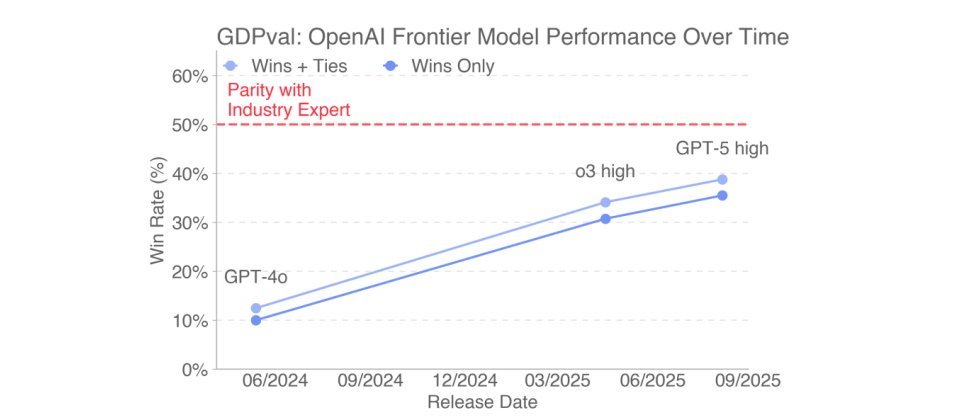
OpenAI在GDPval评估中测试了多个前沿AI模型,包括自家的GPT-4o、o4-mini、OpenAI o3以及旗舰级的GPT-5,同时也纳入了其他主要厂商的模型,如Anthropic的Claude Opus 4.1、Google DeepMind的Gemini 2.5 Pro,以及xAI的Grok 4。
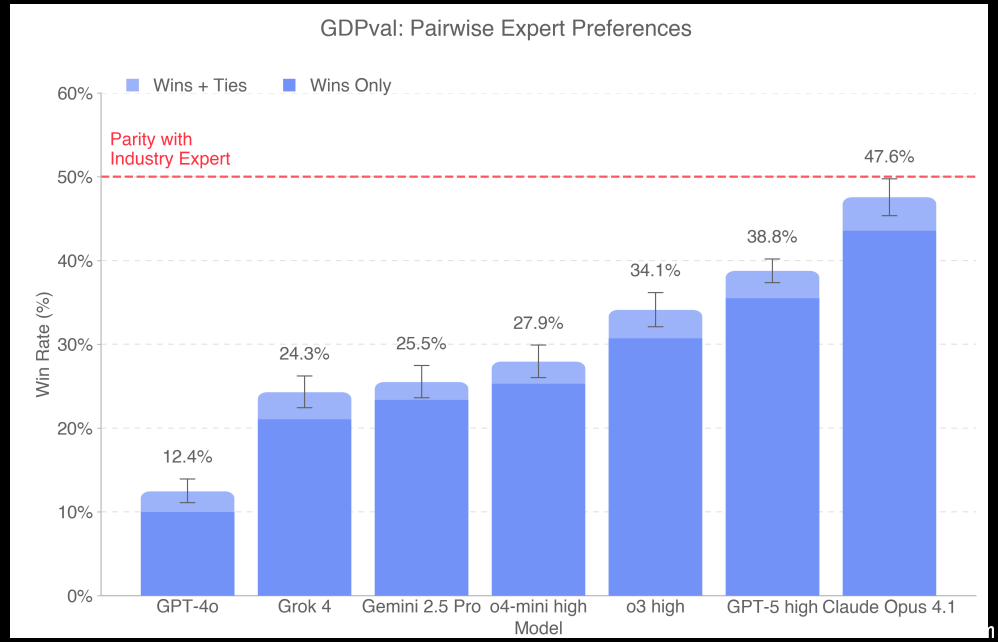
评测结果显示,Claude Opus 4.1在整体表现上略优于其他模型,尤其在文档格式、美观性和排版设计等方面得分最高,输出成果最接近人类专家水平;GPT-5则在专业知识准确性、推理深度和任务完整性方面表现最佳,能够更精确地处理复杂的跨领域问题。相比之下,Gemini 2.5 Pro与Grok 4在部分任务中表现稳定,但在专业细节把握和输出一致性方面仍有一定差距。
OpenAI指出,GDPval的结果表明,当前AI模型已能以100倍的速度和1%的成本完成部分专业任务。未来,在重复性高、规则明确的知识型工作中,AI有望成为有效的辅助工具,帮助人类释放更多时间用于创造性与决策类工作,从而为整体经济增长带来显著潜力。