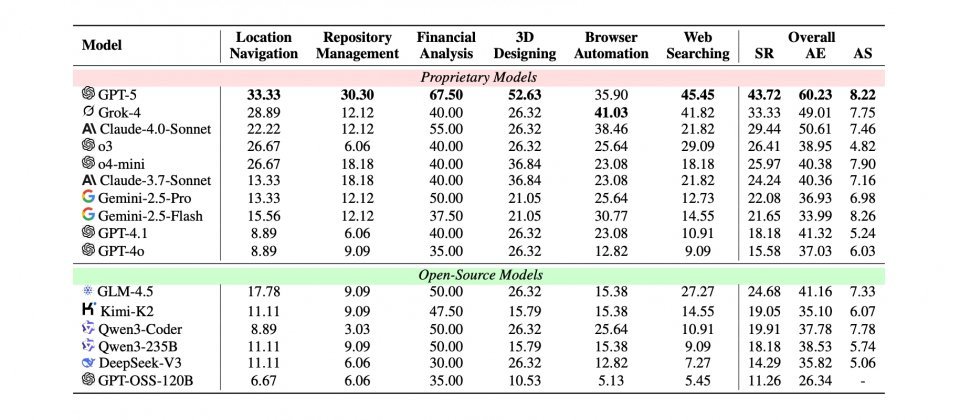
由Salesforce人工智慧研究团队提出的最新MCP-Universe基準测试显示,OpenAI的GPT-5在连结工具并完成多步骤任务场景的整体成功率为43.72%,虽然已经是所有受测模型中最高,但仍未突破一半,突显代理型AI在实务应用上可靠性不足。研究同时指出,长脉络处理与面对陌生工具时的适应力,是目前主要的限制。
MCP-Universe以MCP(Model Context Protocol)作为统一介面,直接串接实机MCP服务器,让模型必须在实际环境中完成操作。测试涵盖六大领域,包括地理导引、版本库管理、财务分析、3D设计、浏览器自动化以及网页搜寻,总共涵盖11个服务器231项任务。这样的设计有别于传统的静态资料集,更能检验模型真实应用场景的多轮规画与工具协作能力。
评分方式採用执行式评估,并非单纯依赖大型语言模型的主观判断,评估项目分为格式检查、静态比对与动态测试,其中动态测试会即时抓取正确的外部资料,例如股价、票务或天气资讯,用于时间敏感型任务。这样的设计能更贴近实务需求,同时确保在不同测试时点也能维持一致的评估基準。
在多模型对照中,GPT-5的43.72%成功率居首,xAI的Grok-4为33.33%,Anthropic的Claude-4.0-Sonnet则为29.44%。研究人员进一步分析指出,当互动步骤增加导致脉络过长,或遇到参数格式各异的工具时,模型表现会明显下滑。此外,子领域成绩落差也相当大,例如GPT-5在财务分析任务中达到67.5%的成功率,但在地理导引与版本库管理上表现不佳。
实际任务包含透过Google Maps MCP规画会面地点、在GitHub MCP进行版本控制操作、以Yahoo Finance MCP进行股市分析、使用Blender MCP处理设计任务、透过Playwright MCP自动化浏览器操作,以及利用Google Search MCP与Fetch MCP进行资讯检索。这些任务都要求模型能正确理解指令,并在实机限制下执行操作并回报结果。