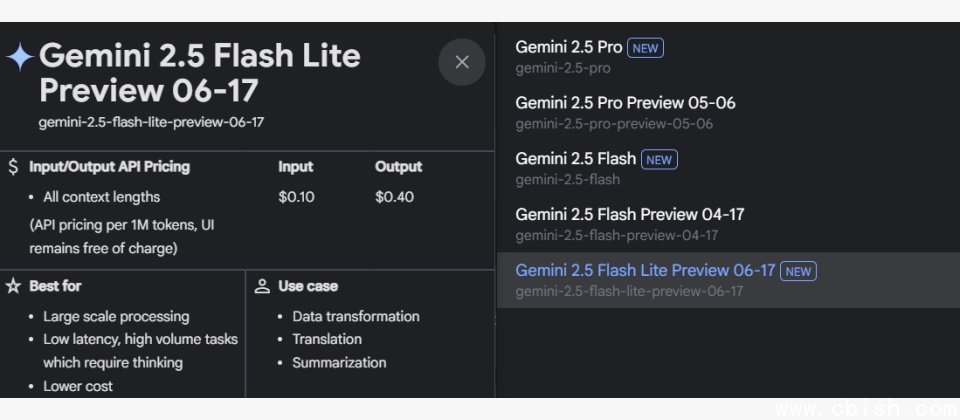
Google在本周二(6/17)正式释出已预览数月的Gemini 2.5 Flash与2.5 Pro稳定版,同时宣布预览入门级的Gemini 2.5 Flash-Lite。
首个具备思考(Thinking)能力的Gemini模型是Google是在去年12月发表的Gemini 2.0 Flash Thinking Mode,而今年开始测试的Gemini 2.5家族则是首个内建Thinking能力的Gemini模型家族,包括Gemini 2.5 Pro与Gemini 2.5 Flash。
此一Thinking能力指的是模型在生成回应之前,会先进行内部推理、分析与规画,以产生更精确也更深入的回答,旨在支援複杂任务的处理,回应时间也会比较久,内建思考能力的大型语言模型亦被外界称为推理模型。
在Gemini 2.5模型家族中,2.5 Pro与2.5 Flash内建并启用Thinking能力,而Gemini 2.5 Flash-Lite的Thinking能力虽然也是内建的,但预设值是关闭的。
一般而言,开发者可以透过API来设定thinkingBudget参数,以决定模型所投入的Thinking资源。在目前的Gemini 2.5模型家族中,2.5 Pro版的thinkingBudget最低阀值是128个Token,意谓着它不论如何都会发挥Thinking能力,也代表着它无法被关闭。
至于2.5 Flash虽然也是预设启用Thinking,但可将thinkingBudget设为0,以关闭其思考功能;至于Gemini 2.5 Flash-Lite预设值则是关闭了Thinking,可藉由thinkingBudget设定来启用。而且在2.5 Flash与Gemini 2.5 Flash-Lite中,不管有没有启用Thinking的费用都是一样的。
最新的Gemini 2.5 Flash-Lite就是讲求成本与效率,每100万个Token的输入费用为0.1美元,输出为0.4美元。而2.5 Flash的输入/输出费用则是0.3/2.5美元,2.5 Pro则是1.25/10美元。
而在Google的各式基準测试中,可以发现启用Thinking的测试结果绝大多数都优于未启用。
除了Thinking功能之外,3个模型都支援多模态输入,包括文字、程序码、图片、声音、影片与PDF等,在输出上,2.5 Pro与2.5 Flash支援文字、程序码,以及文字+图片的输出,2.5 Flash-Lite则仅支援文字与程序码的输出。
此外,2.5 Pro适用于高阶决策、商业分析、複杂的程序码生成及除错;2.5 Flash可支援即时聊天、客服、快速摘要或图片标注等;入门款的Gemini 2.5 Flash-Lite则适用于大规模内容摘要、高吞吐量的资料处理、基本问答与低延迟应用。