Gemini 3 Flash:谷歌的“AI主力引擎”正式上线
谷歌正在全面提速其下一代AI模型的落地节奏,而Gemini 3 Flash,正是这场变革的核心。它不是又一个参数更大的“性能秀”,而是一款真正为规模化、高频次、低成本应用打造的实用型AI引擎。
从名字就能看出它的定位——“Flash”,快、轻、省。它在保持接近顶级模型推理能力的同时,把响应速度提升约3倍,成本压缩至行业最低水平之一,成为开发者、企业、乃至普通用户都能“用得起、用得爽”的AI工具。
全平台覆盖,AI已融入谷歌生态血脉
Gemini 3 Flash 不再是实验室里的原型,它已深度嵌入谷歌全家桶:
- 直接驱动 Google 搜索中的 AI 模式,你下次搜索“今天北京天气怎么样?”时,那个快速生成的总结,很可能就来自它;
- 内置在 Google Gemini 应用中,成为你手机端的智能助手;
- 通过 Gemini API、Google AI Studio、Vertex AI 向开发者开放,支持一键接入;
- 在 Gemini Enterprise 中为企业客户提供安全可控的私有化部署方案;
- 甚至已集成进 Android Studio,帮助开发者自动生成代码片段、调试建议,提升开发效率。
这意味着,无论你是普通用户、创业者,还是大型企业的技术团队,你已经在使用或即将接触到 Gemini 3 Flash 的能力——它正从后台走向前台。
性能炸裂,却只用一半的代价
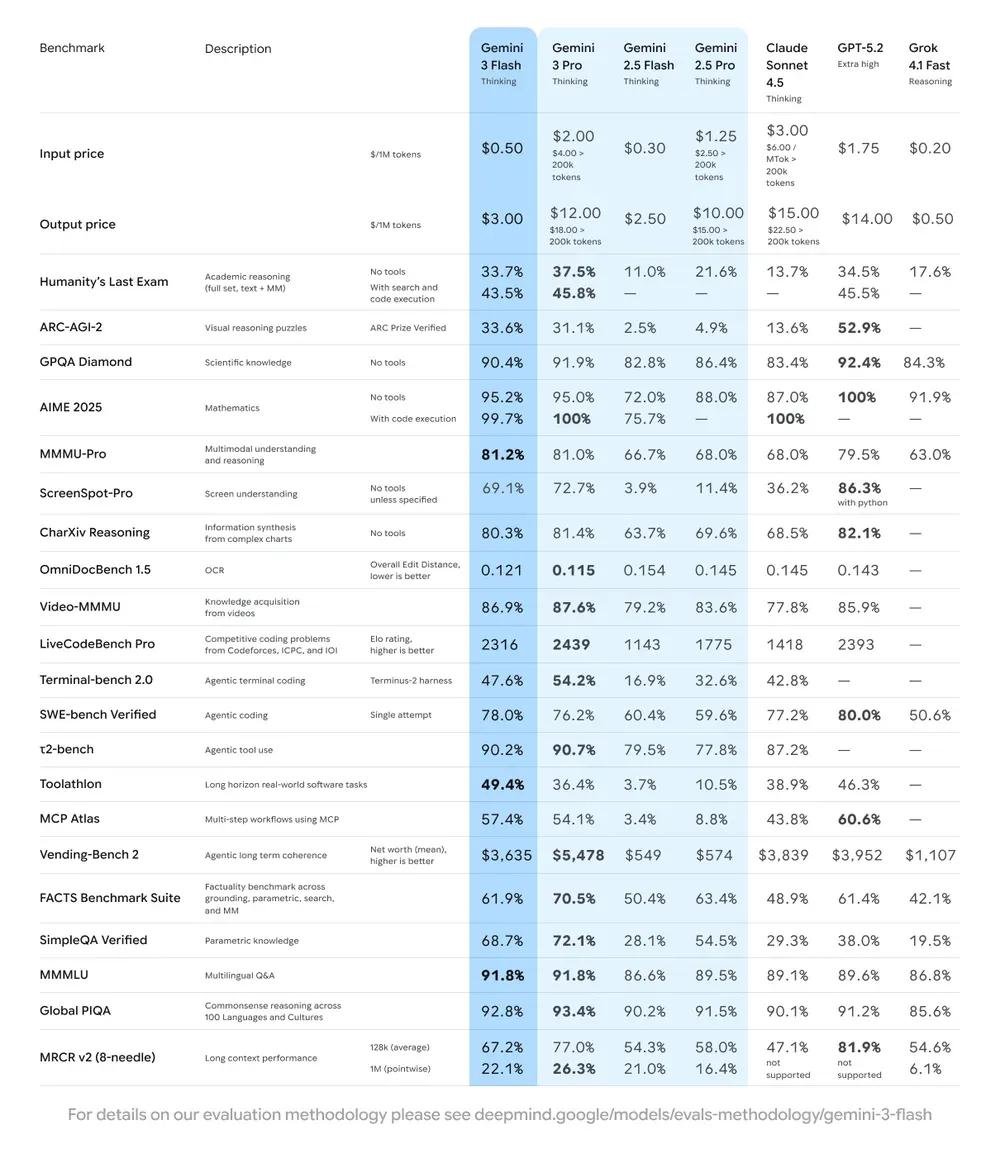
别被它的“轻量”名字骗了。Gemini 3 Flash 在多个权威基准测试中表现惊人:
- 在高难度的 GPQA Diamond(全球专业级问答)中,准确率高达 90.4%,超越前代 Gemini 2.5 Pro,直逼 GPT-4o 级别;
- 在多模态理解测试 MMMU Pro 上达到 81.2%,能准确理解复杂图表、文档、图像中的信息;
- 在代码能力测试 SWE-bench Verified 中拿下 78% 的通过率,意味着它能真实理解开源项目结构,协助修复真实代码缺陷——不是演示,是能上生产环境的水平。
更关键的是,它比同性能模型快3倍,成本却低得多:每百万输入 token 仅 0.50 美元,输出 token 3 美元。对比 OpenAI 的 GPT-4o(输入约5美元,输出15美元),成本优势一目了然。
智能省资源,真正“按需付费”
谷歌没有止步于静态定价。Gemini 3 Flash 引入了动态计算机制:系统会根据你的问题复杂度,自动调整推理深度。简单问题用轻量路径,复杂任务才启动高精度模式。
这一设计让实际使用中的 token 消耗平均再减少 30%。也就是说,你花的钱,比标价更低。对于每天调用成千上万次的App、客服系统、自动化工具来说,这直接决定了商业可行性。
不只是“快”,更是“稳”
很多模型跑得快,但一到真实场景就“幻觉”频出。Gemini 3 Flash 的突破在于——它在速度和可靠性之间找到了最佳平衡点。
在企业级应用中,它已用于自动生成客户支持回复、分析日志、提取合同关键条款;在开发者工具中,它能准确理解项目上下文,给出不会破坏架构的代码建议;在搜索中,它能快速整合多源信息,避免给出矛盾答案。
谷歌内部人士透露,Gemini 3 Flash 已成为公司内部 AI 任务的默认首选模型,日均调用量超百亿次。这不是宣传,是真实业务的选择。
AI普及的拐点,正在到来
过去,高性能AI是大厂的专利;现在,Gemini 3 Flash 让中小企业、独立开发者、甚至个人创作者,都能以极低成本接入世界顶级AI能力。
它不是为了炫技,而是为了让AI真正“用起来”。从搜索框里的一个回答,到你写代码时的自动补全,再到企业后台的自动化流程——它正无声地渗透进我们每天的数字生活。
如果你还在观望AI能为你做什么,现在就是最好的入场时机。因为谷歌已经把“好用、便宜、够强”的AI,摆在了你面前。