
AMD执行长苏姿丰在美国圣荷西正式发表Instinct MI350系列GPU,结合气冷及液冷机柜设计,抢攻全球AI资料中心、大规模AI基础建设市场。
图片来源:AMD
AMD在美国圣荷西市正式发表了採用新一代CDNA 4架构的资料中心AI加速器Instinct MI350系列,採用3奈米製程,内含1,850亿电晶体,相较于前一代提升4倍的AI运算能力,35倍的推论能力提升,而因应资料中心大量AI运算需求持续增加,AMD大胆预告其机架级产品的能源效率,将以2030年提升20倍能源效率为目标。
AMD执行长苏姿丰指出,到2028年预估全球AI推论需求年複合成长率将超过80%,综合AI训练及推论需求,全球资料中心的AI加速运算市场年複合成长将超过60%,预计到2028年全球AI资料中心加速运算市场规模将成长到超过5,000亿美元的规模。
苏姿丰进一步说明AMD的AI市场3大策略,首先是提供AMD的CPU、GPU、DPU各种运算产品组合,其次是支援各种函式及模型,以扩大支援建立开放生态系,最后是提供完整的软件及硬件方案,以支援各种的AI创新应用发展。
扩大生态系方面,今年大会AMD宣布ROCm 7软件堆叠,为AMD最新的开源软件堆叠,支援更多的函式库及AI模型,包括从Day 0就与主要的模型业者合作,并且提供开发人员及开源社群使用的Developer Cloud,供开发人员快速设定试用AMD的AI运算服务,提供25个小时的Instinct 300系列GPU供免费使用,以拉拢吸引开发社群。
在产品方面,AMD更新旗下的资料中心Instinct系列AI加速器产品。自2023年推出Instinct MI300系列,去年更推出标榜效能更佳的Instinct MI325X,均採用CDNA 3架构,而在今年美国圣荷西举办的全球发表活动,AMD如预期正式发表Instinct MI350系列GPU,将Instinct AI加速器架构推进至新一代的CDNA 4架构。
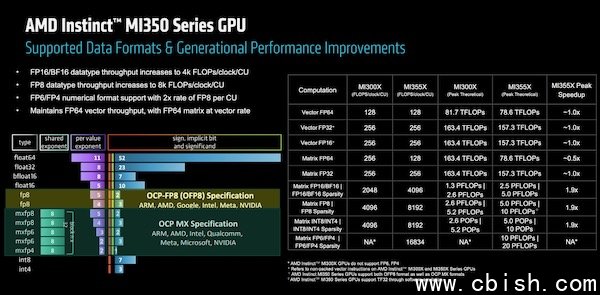
新的CDNA 4架构特别针对GenAI及LLM改善矩阵引擎,并且新增资料格式,以支援混合精度运算,不仅如此,在新架构中也改善Infinity Fabric及先进封装连接能力,综合这些新增及改进,带来能源效率方面的提升,特别是在资料中心的能源限制之下,提高AI加速运算效能。

在新的架构设计特色之下,新的MI350系列GPU内部整合8个XCD(Accelerator Complex Die),每个XCD有32个CDNA 4 CU(Compute Units),加快AI推论及训练能力,FP4及FP6之下效能达到20PF,AMD宣称其效能要比前一代的MI325X提高4倍。
MI350系列整合的HBM3E记忆体容量也有提升,从MI325X的256GB HBM3E记忆体,在CDNA 4架构改进之下增加至最高288GB HBM3E记忆体,频宽达每秒8TB,使得单一GPU能够支援520B参数规模的AI模型。
相较于旧的CDNA 3架构MI300系列GPU,採用新架构的MI350系列GPU,在HBM记忆体的每瓦频宽读取效能提高1.3倍;MI350系列GPU内整合的256个CDNA 4 CU,每个CU的尖锋HBM记忆体读取频宽则提高1.5倍。
如下图所示,AMD比较CDNA 3旧架构的MI300系列GPU,以及採用全新CDNA 4架构MI350系列GPU,在不同资料格式之间的AI生成效能表现:
AMD不忘以MI350系列和竞争对手Nvidia作比较,以AMD MI355X与Nvidia B200、GB200相比,在DeepSeek R1 FP4之下,MI355X较B200的效能表现高出1.2倍,而在Llama 3.1 405B方面,MI355X比B200、GB200,分别高出1.3倍及1倍。
强化AI系统设计及整合能力抢攻全球AI基础建设商机
相较于Nvidia以AI Infrastructure自许,在全球各地与政府及企业合作,大力抢攻AI基础建设市场版图,AMD也不落人后,去年AMD以49亿美元併购ZT System,强化自身的AI系统整合能力,儘管上个月再出售ZT System,但AMD也取得AI系统设计及整合能力,强化自身的AI资料中心方案。
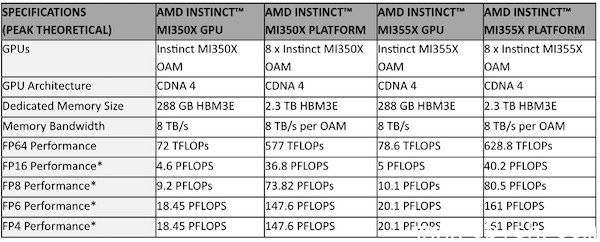
以这次发表的MI350系列为例,AMD称MI350系列是专为现代AI基础建设所设计,MI350系列GPU分为两种版本,用于气冷的MI350X,还有用于直接液冷设计(DLC)的MI355X。
MI350X与MI355X在单颗GPU硬件规格上相同,但是採用气冷的MI350X和液冷的MI355X,两者在效能表现上则有差异:

在8颗GPU组成的平台(Platform)部分,AMD展示第5代EPYC CPU,搭配8颗Instinct MI350系列GPU、400 Gbps NIC/Stoage组成的平台,其中8颗Instinct MI350系列GPU之间,可以每秒153.6GB的Infinity Fabric互连,GPU以外则是使用每秒128GB的PCIe Gen 5连接CPU及储存系统。
8颗MI350X系列GPU组成的平台效能方面,HBM3E记忆体容量可扩充到2.3TB,根据AMD提供的数据,FP4/FP6效能从单颗MI 350X的18.45PF、单颗MI 355X的20.1PF,在8颗GPU组成MI350系列平台后,达到8颗MI350X的147.6PF、8颗MI355X的161PF,不同资料精度格式的效能表现:
在更大的机柜组态方面,气冷的MI350X适用于4U的机架式设计,在气冷式散热的机架下,最高支援到64颗GPU,记忆体最高到18TB HBM3E;而液冷的MI355X适用于10U与2U机架,在液冷式机架设计下,最多支援到128颗GPU,记忆体最高到36TB HBM3E。

AMD也强调Instinct MI350系列GPU,採用OCP(Open Compute Project),以及UEC(Ultra Ethernet Consortium)的业界开放标準,以强调和其他对手提出自己规格之间的差异。
AMD也提前秀出代号为Helios的下一代AI机架设计,将会採用更新一代Instinct MI400系列GPU,搭配代号为Venice,採用新CPU架构Zen 6架构的EPYC CPU,以及称为Vulcano的Pensando NIC。整合更多的记忆体、更大的记忆体的频宽,提升AI运算效能。
Instinct MI350系列GPU预期会在今年下半年推出,首波已有云端运算服务商将与AMD合作,AMD宣布已和Oracle Cloud合作推出OCI的AI基础运算服务,将採用13万多颗的MI355X建立Zetascale的AI运算丛集,以支援大规模的AI训练及推论运算需求。
至于已与AMD合作的Meta,先前採用Instinct 300X系列GPU,用于Llama 3及Llama 4推论,Meta虽未说明未来是否採用MI350X系列GPU,但在发表活动中,对于新一代MI350X系列GPU的效能、每瓦效率表示乐观的态度,AMD也宣布将和Meta合作Insinct MI400平台的相关计画。
另外,AMD此次活动也说明在AI策略上与红帽合作,通过Red Hat OpenShift AI,结合AMD的Instinct GPU,强化在混合云环境里的AI高效能、效率处理能力。
在今年发表MI350系列之后,接下来将在2026年推出MI400系列GPU,将支援最大432GB的HBM 4记忆体,记忆体频宽达到每秒19.6TB,其机架方案效能将比MI350系列提升10倍。
AMD也揭露明年将推出的下一代EPYC处理器Venice,将採用2奈米製程、最高有256个Zen 6 CPU核心, 2倍的CPU与GPU连接频宽,效能为前代产品的1.7倍。
鉴于云端大规模资料中心及企业资料中心的AI运算需求增加,耗电也随之增加,AMD也提出新的能耗目标,指出Instinct MI350系列已超出AMD将AI训练和高效能运算节点能源效率提升30倍的5年目标。该公司也提出2030年的新目标,以2024年为基準,2030年将机架级的能源效率提升20倍,以现今需要超过275机架的AI模型,在2030年在单一机架内训练,并降低9成5耗电。