 图片来源:
图片来源: 微软
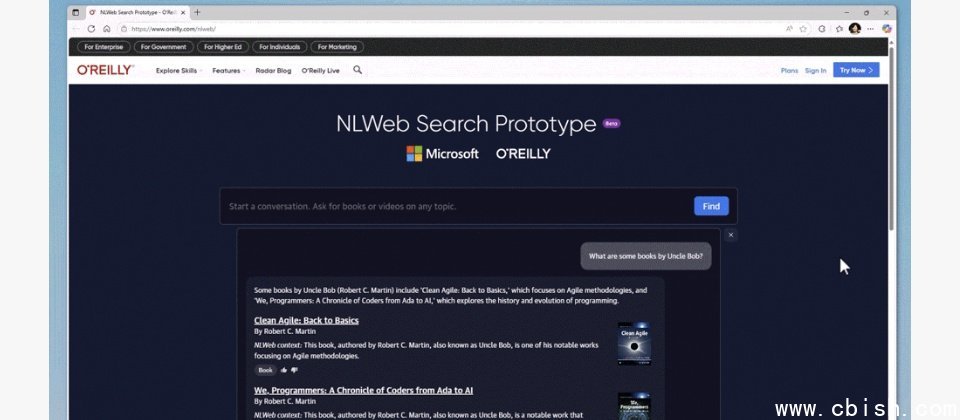
微软周一(5/19)透过GitHub开源了NLWeb专案,它的全名为Natural Language Web,导入NLWeb的网站将可让使用者以自然语言查询网站资料。简单地说,启动NLWeb服务之后,网站便可接上如同ChatGPT般的对话介面。
NLWeb是由曾发明内容订阅协定RSS、网页内容标注标準Schema.org,以及资源描述框架RDF的R.V. Guha所构思及开发,已担任十多年Google院士的Guha最近加入了微软,成为微软院士暨企业副总裁。
根据微软的说明,NLWeb是利用包括Schema.org与RSS等半结构化的格式,以及网站已发布的其它资料,再透过基于大型语言模型(LLM)的各种工作,来建立可同时供人类及AI代理使用的自然语言介面。
每一个NLWeb实例都是一个模型脉络协定(Model Context Protocol,MCP)服务器,让网站得以开放自己的内容,以供其它代理或MCP生态系统的参与者发现及存取。微软期望NLWeb最终可在新兴的代理网页(Agentic Web)中扮演类似HTML的基础角色。上述的MCP是由Claude模型开发商Anthropic所开源的标準,让AI助理得以透过该协定存取所有资料来源。
NLWeb系统可藉由整合底层LLM的外部知识来强化此一结构化的资料,例如在餐厅的查询中加上地理资讯,以带来更丰富的使用者经验。
微软亦强调,作为一个开源专案,NLWeb将保持技术中立,支援所有主流作业系统,也允许开发者自由选择最适合的元件,涵盖各种模型与向量资料库。