 图片来源:
图片来源: Nvidia
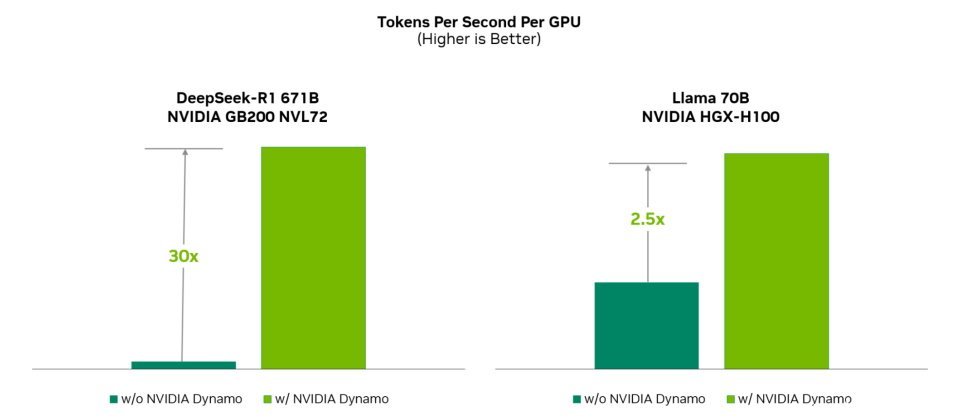
Nvidia周二(3/17)开源了全新的推论软件Dynamo,它可大幅提高推论性能,令Llama模型的推论性能及营收提高一倍,也能在执行DeepSeek-R1模型时,让每个GPU产生的Token数量增加逾30倍。
Nvidia解释,随着AI推理(reasoning)成为主流,每个AI模型都会在每次提示时产生数以万计、用来思考的Token,若能增加推论(inference)效能并持续降低推论成本,将可加速成长并提高服务供应商的收入机会。
随着模型变得愈来愈大,并且愈来愈融入需要与多个模型互动的AI工作流程中,大规模部署这些模型涉及到将它们分布在多个节点上,也需要跨GPU进行仔细的协调。
Dynamo是Nvidia既有Triton Inference Server的继任推论软件,主要利用分解式服务(disaggregated serving)将大型语言模型的处理阶段与生成阶段,分别部署在不同的GPU上,以提升性能与效率。

图片来源/Nvidia
Dynamo的4个关键元件分别是GPU资源规画器、智慧型路由器、低延迟通讯库,以及KV快取管理器。其中,GPU资源规画器是个规画及调度引擎,可依据不断变化的使用者需求,动态新增或删除GPU,以避免GPU太多或不足;智慧型路由器则是一个可理解大型语言需求与特性的路由器,能够在大规模部署的GPU群组中,将请求分配到最适合的GPU上进行处理,并减少对于重複请求的重新运算,让所释放的GPU资源得以处理新的请求,节省运算资源。
低延迟通讯库是个针对推论最佳化的工具集,可支援不同GPU之间、以及不同类型的记忆体及储存类型的资料传输,以提高推论效率。KV快取管理器是个快取卸载引擎,会根据需求将KV快取资料转移到不同的记忆体储存层次中,以释放宝贵的GPU记忆体,同时保持用户体验。
根据Nvidia的测试,使用相同数量的GPU,若在Hopper平台上执行各种Llama模型,Dynamo能使AI工厂的性能和营收翻倍;在 GB200 NVL72机架的大型丛集上执行DeepSeek-R1模型时,Dynamo也能将每个GPU产生的Token数量,提高超过30倍。