微软发表Phi-4-multimodal,这是一款小型语言模型(SLM)具备处理语音、图像与文字的能力,已于Azure AI Foundry、Hugging Face及Nvidia API Catalog上线。相较于过去的Phi-3.5及Phi-4.0,这次的版本不仅提升了多模态整合能力,也强化了语音辨识、视觉理解与推理能力,适用于开发多元人工智慧应用的场景。微软强调,Phi-4-multimodal针对运算资源受限的环境进行最佳化,能够在装置端执行。
在非多模态架构下,语音输入通常需先透过语音辨识技术转换为文字,而影像则可能需透过独立的视觉模型处理,之后再进行语言理解或跨模态分析。这种方式不仅增加延迟,也无法充分利用语音中的额外资讯,例如语调、语境或背景音。Phi-4-multimodal则透过统一的神经网路架构,直接对语音、图像和文字进行处理,减少资料转换过程的资讯流失,并提升整体处理效率。
技术规格上,Phi-4-multimodal具有56亿参数,支援12.8万Token的上下文长度,并透过监督式微调、直接偏好最佳化(DPO)与人类回馈强化学习(RLHF)等方式,提升指令遵循能力与安全性。在语言支援方面,文字处理涵盖超过20种语言,包括中文、日文、韩文、德文与法文等,语音处理则涵盖英语、中文、西班牙语、日语等主要语种,图像处理目前则以英文为主。
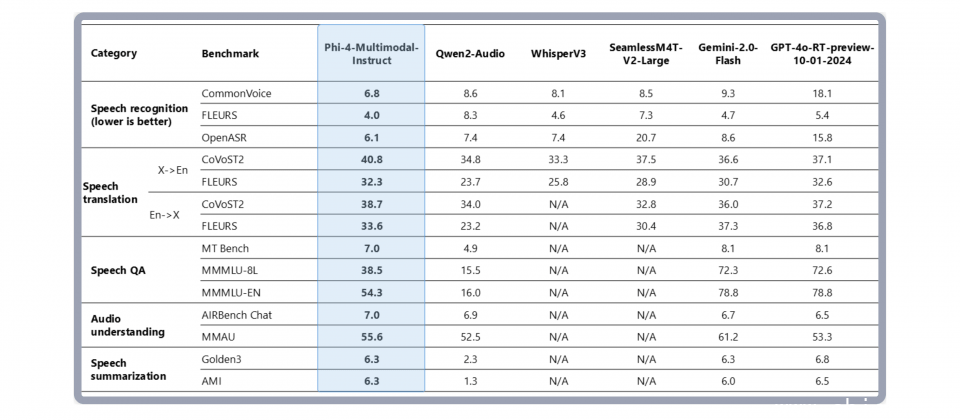
Phi-4-multimodal的一大亮点在于语音处理能力,特别是在语音辨识与语音翻译方面,已超越WhisperV3及SeamlessM4T-v2-Large,并在Hugging Face OpenASR排行榜上达到只有6.14%的字错率(WER),优于WhisperV3的最佳成绩6.5%。此外,这款模型也在数学与科学推理测试中表现出色,并在OCR、图表理解与文件推理等应用可与其他大型模型竞争,如Gemini-2.0-Flash Lite与Claude-3.5-Sonnet。
除了多模态模型,微软也推出Phi-4-mini,这是一款38亿参数的小型模型,专注于文字处理,特别适用于程序码生成、数学推理、长文本处理与函式呼叫。Phi-4-mini採用分组查询注意力机制(Grouped-Query Attention),提升计算效率,也支援12.8万Token内容,在同等级的小型语言模型中拥有更强的推理与指令遵循能力。
微软与OpenAI的合作仍然持续,但在小型语言模型(SLM)领域,微软也积极发展自家技术,以补足OpenAI大型模型之外的应用需求。与GPT-4等大规模模型不同,Phi-4-multimodal及Phi-4-mini採用较小的参数规模,针对低延迟推理与计算资源受限的场景进行最佳化,适用于边缘设备、嵌入式应用及行动装置。这类小型模型的发展,也反映出人工智慧应用在云端与装置端的多元部署策略,让智慧设备能够更高效地处理多模态输入。