 图片来源:
图片来源: Meta
继于今年4月发表可用来分割图像物件的Segment Anything Model(SAM)之后,Meta周一(7/29)释出Segment Anything Model 2(SAM 2),并将分割物件的功能从图像延伸到影片。
SAM 2可以分割图像或影片中的任何物件,还能即时于影片中的所有画面追蹤该物件,既有的其它模型无法实现此一功能,是因为它比分割图像中的物件还要困难许多。在影片中,物件可以快速移动,外观可能有所改变,也可能被场景中的其它物件挡住。
Meta说明,SAM可理解图像中物件的一般概念,而图像可被视为只有一个画面的短影片,Meta即採用此一概念来开发一个统一的模型,得以同时支援图像与影片的输入,处理影片的唯一区别是,该模型必须依赖记忆体来回忆之前处理过的影片资讯,以于当前的时间準确分割物件。
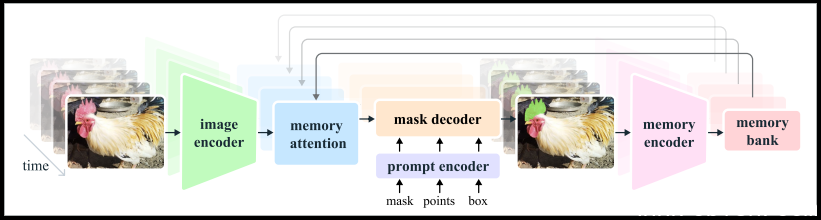
图片来源/Meta
要成功分割影片中的物件,需要了解实体于空间与时间中的位置,相较于图像中的物件分割,影片中的物件移动、变形、遮挡、照明变化或其它因素,都可能在不同的画面之间发生重大变化,再加上影片品质通常低于图像,更增加了难度。于是Meta藉由建立新的影片物件分割资料集(SA-V Dataset)来训练SAM 2。

图片来源/Meta
SA-V Dataset包含了5.1万个真实世界的影片,以及超过60万个时空掩码(Masklet),Masklet标注了物件于画面中出现的时间点与位置。相较于坊间最大的影片分割资料集,SA-V Dataset的影片数量是它的4.5倍,标注数量则是53倍。
自释出图像物件分割模型SAM以来,除了Meta的内部应用外,SAM已被应用在海洋科学中以分割声纳图像或分析珊瑚礁,亦已被应用在救灾的卫星图像分析,以及医疗领域上的细胞图像分割,并协助检测皮肤癌。Meta更预期可同时分割影像及影片物件的SAM 2可望被用在自动驾驶系统,追蹤濒临绝种的动物,或是应用在医疗领域的腹腔摄影镜头上,相信它有更广泛的可能性。
SAM 2程序码及权重採用Apache 2.0开源授权,SAM 2评估程序码则採用BSD-3开源授权,而SA-V Dataset亦透过CC BY 4.0授权与外界共享。使用者可透过SAM 2的展示网站理解它的能力。