 图片来源:
图片来源: 微软
微软的AI研究团队近日发表了一份名为SpreadsheetLLM的研究报告,旨在协助大型语言模型(LLM)更容易理解试算表(Spreadsheet)中的资料,以便正确推论。
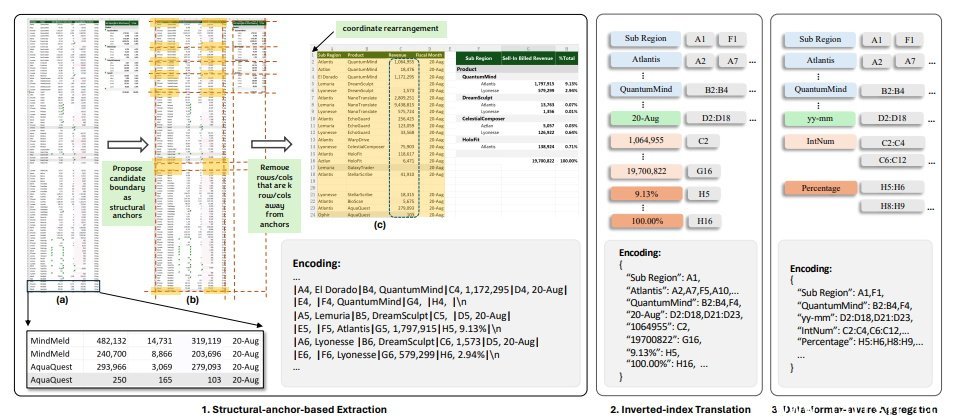
试算表由许多储存格组成,这些储存格存放着文字、数字、公式或函数,嵌入在许多的行与列当中,形成灵活且複杂的大规模二维结构,同时它还具备了诸如字体、颜色或边框等各种格式选项,对大型语言模型造成了重大挑战,于是研究人员开发出SpreadsheetLLM框架,以协助LLM理解并正确推论来自试算表的内容。
研究人员指出,他们一开始利用一个简单的序列化方法,结合了储存格位址、值与格式,但此一方法受到大型语言模型所支援Token数量的限制,在大多数的应用中无用武之地;于是他们进一步开发了可用来编码及压缩试算表的SheetCompressor,它包含3个模组,一个用来压缩试算表结构,一个反向索引翻译,以及一个可感知资料格式的聚合模组,结果在GPT4的脉络学习设定中,后者的性能比前者高出了25.6%。
此外,当微调大型语言模型并辅以试算表压缩比达25倍的SheetCompressor时,其用来测试模型準确度的F1分数达到78.9%,大幅超越了现有最佳模型的12.3%。
之后研究人员再提出了试算表链(Chain of Spreadsheet),用以理解试算表的下游任务,并于新的试算表QA任务中进行验证,证实了SpreadsheetLLM在许多试算表任务中都非常有用。

图片来源/微软
在该研究所描绘的SpreadsheetLLM流程中,是以SheetCompressor结合各种不同的大型语言模型来理解试算表,再针对试算表的各种下游任务进行推论。
研究人员指出,SpreadsheetLLM为处理及理解试算表的重大进步,它有效地解决了尺寸带来的挑战,以及试算表固有的多样与複杂性,可大幅减少所需的Token及运算成本,而能在大型资料集上进行实际的应用,对各种LLM的微调更可进一步提高对试算表的理解能力。至于用来扩充SpreadsheetLLM框架的Chain of Spreadsheet则展现了未来的应用潜力,也将带来更有效与更聪明的使用者互动性。