 图片来源:
图片来源:
Hugging Face
Meta周四(6/27)发表了LLM Compiler,此为奠基于程序码生成模型Code Llama的新模型,额外强化了对编译器中介语言(IR)、组合语言及最佳化技术的理解,可用来改善所生成的程序码品质,目前已可透过Hugging face取得。
Meta表示,LLM Compiler模型能够模拟编译器的功能,得以预测哪些最佳化步骤能够达到最佳的程序码尺寸,或是将以已编译的程序码转换回原本的语言,目前提供7B与13B两种版本,透过相对宽鬆的授权允许研究及商业使用。
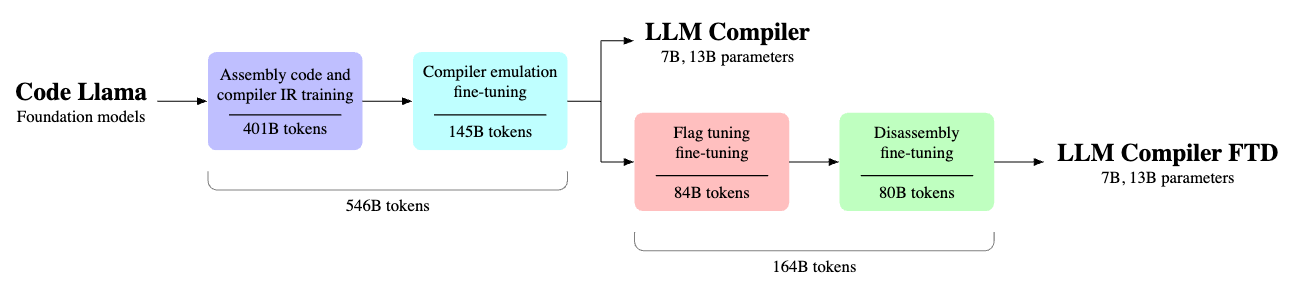
这是因为Meta认为,儘管大型语言模型(LLM)在各种软件工程及程序码任务中展现卓越的能力,但它们在程序码及编译器最佳化领域上的应用,却未得到充分的探索,训练LLM是个资源密集,需要大量GPU时间与大量资料收集、可能令人望之却步的任务,而LLM Compiler即是个专为最佳化程序码任务所设计的预训练模型,并可供公开使用。
LLM Compiler已于5,460亿个LLVM-IR与组合程序码的Token上进行训练,指令亦已经过微调以更好地编译器的行为,开发者可透过客製化的商业授权以进行广泛的运用,现有具备70亿参数及130亿参数的两种模型可供选择。
Meta还展示了经过微调的模型版本,这些版本在优化程序码大小,以及将x86_64和ARM组合语言反组译回LLVM-IR的能力方面取得了显着的进展。具体来说,这些模型可达到77%的程序码最佳化潜力,以及45%的反组译回路,当中的14%是精确匹配的能力。