豆包登顶,国产视觉大模型首次全面超越海外巨头
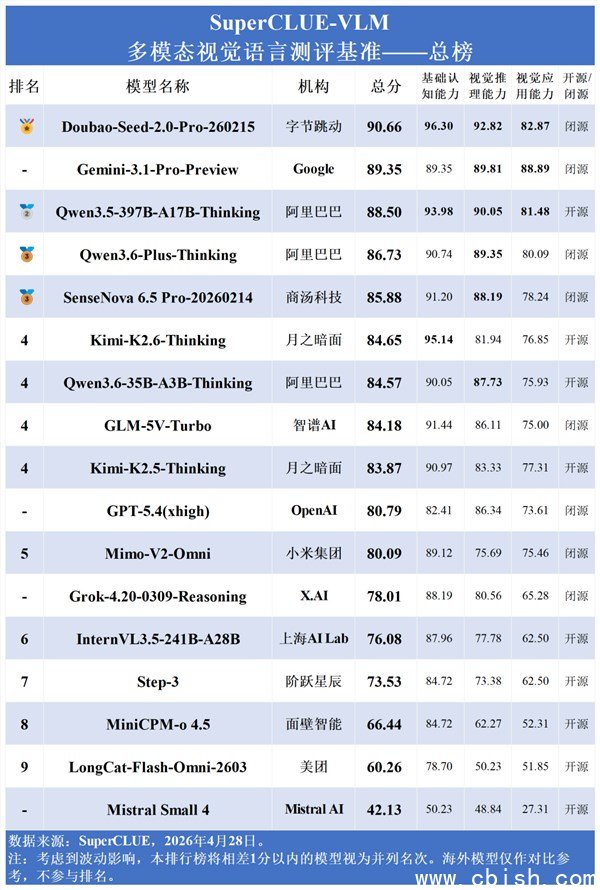
2026年4月,SuperCLUE-VLM发布最新多模态模型评测报告,覆盖全球17款主流AI模型,中文场景表现成为关键分水岭。结果出人意料:字节跳动的“豆包-Seed-2.0-Pro-260215”以90.66分拿下总榜第一,正式超越谷歌Gemini-3.1-Pro-Preview(89.35分),成为首个在中文多模态评测中登顶的国产模型。
这不是个例。阿里Qwen3.5、商汤SenseNova、智谱GLM等国产模型集体杀入前五,几乎包揽了榜单前六名。反观OpenAI的GPT-5.4和X.AI的Grok,虽然在英文场景依旧强势,但在中文图像理解、本地化语义识别上明显“水土不服”,排名跌至中游。一位参与评测的工程师透露:“我们测试了1000多张带中文标语的图片,比如‘扫码点餐’‘限行尾号’,国产模型几乎零误判,而海外模型错得离谱。”
看得懂中文,才能真有用
这次评测不只是比谁“看得清”,更比谁“看得懂”。在25项真实场景测试中,国产模型在“基础认知”和“数据分析”两大模块表现近乎完美——能准确识别外卖单上的手写备注、理解地铁站内中文指示牌的组合含义、从带中文标注的财报图表中提取关键趋势。
一位电商运营人员分享了真实体验:“以前用国外模型分析商品图,它老把‘买一送一’识别成‘买一送二’,现在用豆包,连促销标签的字体歪了、颜色褪了都能认出来,准确率高到让我怀疑是不是人工在后台。”
这些能力不是靠参数堆出来的。背后是大量中文真实场景数据的打磨:从菜市场摊位价签、医院检查单、工厂设备铭牌,到短视频字幕截图、直播弹幕截图,国产模型训练时“吃”的全是中国人天天接触的图像信息。
短板在哪?工业和医疗还没完全跟上
但胜利不是全盘碾压。在“视觉推理”维度,尤其是高精度工业检测和医学影像分析上,国产模型仍显吃力。比如在CT影像中识别微小肺结节、判断电路板焊点是否虚焊,部分模型出现波动,误判率比国际顶尖模型高出15%-20%。
这不是技术不行,而是数据难搞。一位三甲医院AI项目负责人说:“我们有上百万张标注精准的医学影像,但因为隐私和合规,没法全量开放给模型训练。国外模型背后是几十年积累的公开医疗数据库,我们还在爬坡。”
工业领域也类似。汽车厂的质检图像涉及大量 proprietary 工艺参数,厂商不愿共享。相比之下,国外模型早就在特斯拉、西门子的公开数据集上练了多年。
真正的转折点,不是分数,是场景落地
这次榜单的意义,不在于谁拿了第一,而在于——中文世界的AI,终于不再“翻译”西方模型了。
过去,我们用GPT-4V去理解中文海报,用Claude去识别人脸身份证,总要等它“慢慢适应”。现在,豆包能直接认出你手机里那张被揉皱的医保卡,Qwen3.5能从你拍的超市小票里自动帮你记账,商汤的模型甚至能帮你分辨不同品牌酱油瓶的生产日期编码。
这不是实验室里的花架子,是真正在你手机里、在你工作流里,悄悄变好用的工具。技术拐点,从来不是某个模型突然“开挂”,而是你开始觉得:“哦,这个AI,真懂我。”
接下来的竞赛,不再是比谁的参数更大,而是比谁能把中文世界的复杂、混乱、烟火气,真正变成AI的常识。国产模型已经跨过了门槛,接下来,拼的是谁更懂生活。