AI编程工具Cursor发布了自研模型Composer 2,并已在产品中上线使用。该模型主打在保持编程能力的同时降低使用成本,定价为每百万输入标记(Token)0.50美元,每百万输出标记2.50美元。官方还推出一个更快的版本,定价为每百万输入标记1.50美元、每百万输出标记7.50美元,且快速版将作为默认选项。
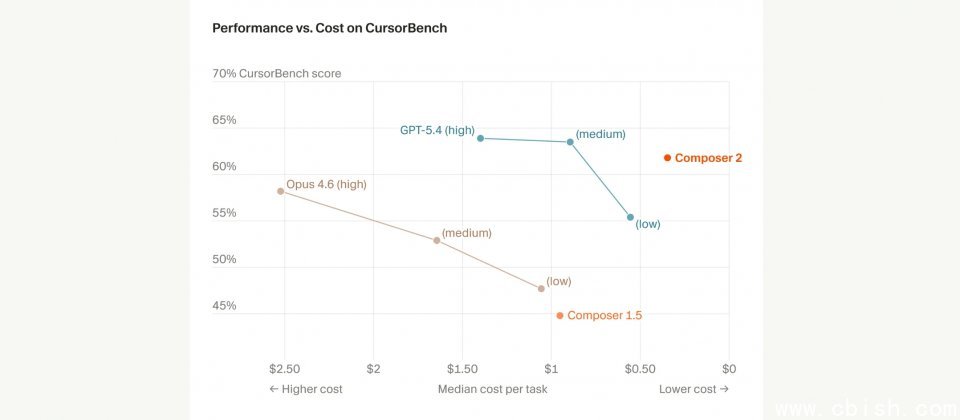
官方公布的CursorBench数据显示,Composer 2在更低的成本下仍保持61.3分,略低于GPT-5.4的high与medium设置,但高于GPT-5.4的low设置,单次任务的中位成本也更低。若与Opus 4.6的high、medium、low三种设置相比,Composer 2则同时处于更高分数和更低成本的位置。
Composer 2在CursorBench得分为61.3,显著高于Composer 1.5的44.2和Composer 1的38.0;在Terminal-Bench 2.0与SWE-bench Multilingual两项测试中,Composer 2分别获得61.7和73.7分,也都优于前两代模型。
Cursor表示,Composer 2的性能提升得益于采用持续预训练,使后续强化学习建立在更强的基础之上,再针对长任务进行训练,从而提升模型处理需要数百个操作步骤问题的能力。官方将这类需要连续执行多步骤操作的编程任务称为“长程编程任务”(Long-horizon Coding Tasks)。
随着开发者越来越多地将AI用于编程、调试与推理等工作,标记成本已成为评估模型时不可忽视的因素。从Cursor此次公布的数据来看,Composer 2不仅在模型能力上有所提升,也试图在性能与使用成本之间取得更具吸引力的平衡。
不过,这组模型比较结果的测试条件并不完全一致。Cursor指出,Anthropic模型的分数采用Claude Code评估执行器,OpenAI模型的分数采用Simple Codex评估执行器,而Cursor自家的分数则依据Terminal-Bench 2.0指定的Harbor评估框架,在默认设置下执行,每组模型与代理组合各测试5次后取平均。因此,这些数据可作为观察模型表现的参考,但若要直接比较不同模型,仍需考虑评估执行方式与测试条件的差异。