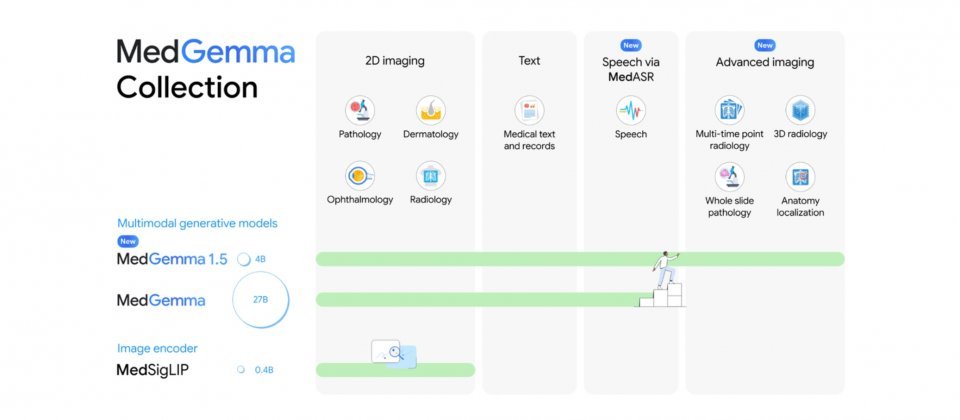
谷歌发布更新开源权重医疗生成式AI模型MedGemma至1.5版本,强化医疗影像解读与医疗文本任务的基准能力,并同步推出医疗语音转文字模型MedASR,满足医疗听写与临床口述记录的转录需求,帮助开发者将语音内容转化为文字后,衔接信息整理或推理任务。
MedGemma是作为开发起点的模型,而非可直接上线的成品系统。谷歌提醒,模型输出不应直接用于临床诊断或治疗决策,实际落地前仍需根据具体场景完成验证与调优。
此次谷歌率先发布MedGemma 1.5的4B多模态版本,主打低算力需求,适合作为评估与微调的起点;若需处理更复杂的文本任务或更大模型容量,开发者仍可使用MedGemma 1的27B版本,包含纯文本与多模态两种变体。相比前一代主要支持2D影像,1.5版扩展了对高维影像的支持,涵盖计算机断层扫描(CT)、磁共振成像(MRI)以及更大尺度的病理影像,并支持通过多张切片或多个影像区块结合提示词完成任务。
谷歌披露了部分内部基准测试结果。以疾病相关的3D影像分类任务为例,MedGemma 1.5 4B在CT上的宏平均准确率由58.2%提升至61.1%,在MRI上则由51.3%提升至64.7%。谷歌指出,这些能力仍处于早期阶段,实际应用中通常需要结合自有数据进行微调,才能在特定流程中获得更稳定的表现。
除高维影像外,MedGemma 1.5还增强了胸部X光的应用场景,例如在不同时点的影像间进行前后对比,或对影像中的解剖结构进行定位。另一项能力是医疗文书理解,例如从检验报告中抽取结构化数据,便于后续统计分析或系统对接。谷歌云还为MedGemma提供了DICOMweb集成,发布支持DICOMweb链接的新容器与部署流程,使应用可通过链接方式在服务器端读取并预处理CT、MRI等影像,再交由模型推理,以降低数据传输负担,更贴近临床系统的集成需求。
同期发布的还有MedASR模型,这是针对医疗术语与临床口述习惯进行微调的自动语音识别模型。谷歌以通用语音识别模型Whisper v3 Large作为对照,在一组胸部X光相关语音数据集中,Whisper v3 Large的词错误率为12.5%,而MedASR搭配6-gram语言模型解码后可降至5.2%。在多个内部医疗听写数据集上,MedASR搭配6-gram语言模型的词错误率约为4.6%至6.9%,而Whisper v3 Large则为25.3%至33.1%。