DeepSeek新论文引爆AI圈:mHC架构背后,V4是否即将登场?
这两天,一篇来自DeepSeek的学术论文在技术圈悄然刷屏。不同于以往那些“加层、调参、换数据”的常规优化,这篇论文提出了一种名为mHC(multi-Hierarchical Context)的全新神经网络架构——它不是对现有模型的微调,而是一次从底层重构注意力机制与信息传递路径的系统性创新。
论文本身技术细节密集,本应属于小众研究范畴,但真正引爆舆论的,是其中一句看似平淡的陈述:
“这一结论得到了我们内部大规模训练实验的进一步验证。”
这句话,像一枚信号弹,瞬间点燃了全球AI社区的想象力。在业内,这种表述几乎成了“我们已经跑完完整训练周期”的暗语——它意味着模型不再停留在小规模实验或仿真阶段,而是已在数千张A100/H100上完成了数周甚至数月的全量训练。
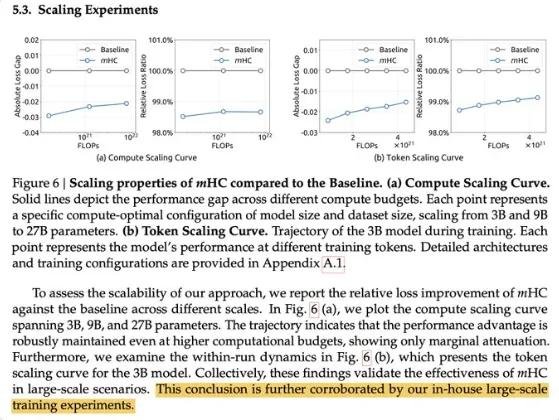
“V4”不是猜测,是逻辑推演
顺着这条线索,海外开发者和研究员开始“考古”DeepSeek的发布节奏:
- 2023年6月:DeepSeek-V1发布,开源7B/67B,性能对标Llama 2
- 2023年12月:DeepSeek-V2上线,首次引入MoE架构,推理成本降低40%,性能逼近GPT-3.5
- 2024年7月:DeepSeek-Coder发布,代码能力登顶Hugging Face开源榜
- 2025年1月:mHC论文曝光,暗示“大规模训练已完成”
时间线清晰得像一份产品路线图。而mHC架构,正是V2中MoE技术的自然演进——它不再只是“专家路由”,而是引入了多层级上下文记忆模块,让模型在长文本处理、多轮推理和跨段落逻辑连贯性上实现质的飞跃。据知情人士透露,该架构能有效缓解传统Transformer在处理>128K上下文时的“注意力坍缩”问题。
目前,业内普遍推测:DeepSeek V4已进入最后阶段——后训练(post-training)、RLHF优化、安全对齐与多语言测试。如果一切按计划推进,发布时间极有可能锁定在1月25日之后,甚至春节前(2月上旬)。这将与Meta、Google等巨头的发布节奏形成鲜明对比,形成“中国AI的春节攻势”。
为什么V4让整个行业屏住呼吸?
不是因为参数更大,而是因为它“不走寻常路”。
当前主流大模型的升级路径几乎同质化:堆算力、扩数据、加层数。但DeepSeek的每一次突破,都直指架构本质:
- V1:证明中国团队能做出开源高质量模型
- V2:用MoE打破“算力军备竞赛”的困局
- V3(未发布):传闻已实现“动态稀疏激活”,推理能耗降低50%
- V4:mHC架构或成下一代长上下文模型的新标准
更关键的是,V4可能不再依赖“海量互联网数据”作为唯一燃料。据论文附录暗示,mHC结构能更高效地利用高质量、小规模的结构化知识(如代码库、数学证明、科学论文),这意味着——它可能在数据效率上实现革命性突破。
这正是OpenAI、Anthropic等团队至今未能解决的难题:如何在不无限扩大训练数据的前提下,持续提升模型推理深度与逻辑一致性。而DeepSeek,正在用架构创新,给出另一种答案。
官方沉默,但市场已沸腾
截至目前,DeepSeek官网和官方账号仍未对V4或mHC作出任何确认。但行业风向已变:
- 硅谷AI初创公司开始紧急评估mHC架构的开源可能性
- 多家国内大厂已内部组建“V4应对小组”,准备提前适配
- 推特上#DeepSeekV4话题单日讨论量突破12万,超越同期Llama 4传闻
有开发者在GitHub上已开始基于论文中的伪代码复现mHC模块,初步测试显示,在10K上下文任务中,其表现优于同等规模的Qwen2和Gemma 2。
我们或许永远无法知道DeepSeek内部的完整计划,但有一点可以确定:当一家公司不再靠“参数喊话”吸引眼球,而是用扎实的架构创新默默推进时,它往往已经准备好下一局的胜负手。
春节前,答案即将揭晓。你,准备好迎接下一个开源大模型的“中国时刻”了吗?