谷歌DeepMind悄然发布DeepSearchQA:一场关于“AI能否像人一样搜索”的真实考验
就在上周,谷歌旗下DeepMind团队在Hugging Face上低调上线了一个名为DeepSearchQA的全新数据集。没有发布会,没有新闻稿,甚至连官方博客都未提及——但这个项目,正在AI圈内悄悄引发一场关于“搜索本质”的激烈讨论。
乍看之下,它只是一个900道问答题的集合:涵盖科技、历史、医学、法律、艺术等17个领域。但真正令人不安的是——这些问题,根本不是“查一下就能答”的那种。它们像一场精心设计的侦探游戏:你必须从一个模糊线索出发,连续跳转多个网页、交叉验证信息、剔除误导内容,甚至要记住前几步的发现,才能拼出完整答案。
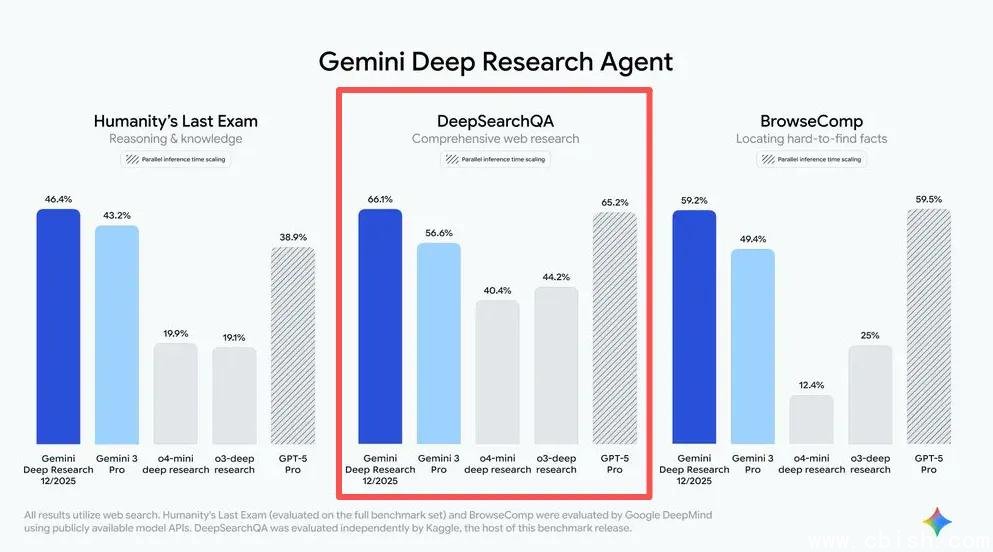
为什么说它比SQuAD、HotpotQA更难?
传统问答数据集追求“精准匹配”:你问“爱因斯坦的出生地是哪?”,答案就是“乌尔姆”。但DeepSearchQA要的不是答案,是“过程”。
举个真实例子: “列出2000年后获得诺贝尔化学奖、且研究方向涉及RNA修饰的女性科学家。” 你不能只搜“诺贝尔化学奖女性得主”——因为很多页面会漏掉“RNA修饰”这个关键限定。你得先查获奖名单,再逐个翻论文摘要,还要交叉比对维基百科、大学官网、期刊数据库,最后排除那些“曾研究过RNA但不涉及修饰”的人。
更狠的是:约65%的问题没有“唯一答案”,而是要求你列出“所有符合条件的项”。这意味着AI不能靠“猜最可能的那个”蒙混过关,它必须确保**没有遗漏**——这正是人类专家在做文献综述时最怕出错的地方。
设计精妙:不让AI“抄近道”
DeepSearchQA的每个问题都配有标准答案和答案类型(如“列表型”“比较型”“因果链型”),但这些信息在测试时**完全隐藏**。也就是说,AI不能靠识别“这题要列五个名字”来作弊。
所有问题都基于公开可验证的网页内容——维基百科、PubMed、政府档案、学术机构页面等。你可以自己打开浏览器,按题目指引一步步搜,最终也能得出相同结论。这确保了评测的公平性:不是在比谁的模型参数更大,而是在比谁的搜索策略更接近人类。
值得一提的是,团队特意避开了“多跳问答”中常见的“合成数据陷阱”。所有问题都源于真实用户在科研、法律咨询、医疗诊断等场景下的搜索行为,不是人工编造的“逻辑谜题”。
局限?有,但正因如此才真实
DeepMind也坦率承认了它的边界:
- 它不看你“怎么想的”,只看你“答得对不对”——所以AI可能靠统计规律“蒙对”,而不是真推理。
- 它假设网络内容是静态的。如果某篇关键论文被删除、某个官网改版,答案可能失效——这正是现实世界中搜索引擎每天都在面对的问题。
- 不适合评测突发新闻或实时事件,比如“2025年最新FDA批准的抗癌药有哪些?”——这不是它的目标。
但正因如此,它才更像一面镜子:它不追求“完美AI”,而是测试“AI在真实信息环境中,能否像一个认真、耐心、有条理的人类研究者那样工作”。
谁该关注这个项目?
如果你是:
- AI研究员:这是首个真正聚焦“搜索规划能力”的公开基准,比MMLU、BIG-bench更贴近实际应用。
- 搜索引擎工程师:你的排序算法、链接分析、去重机制,能不能通过这套题?
- AI产品经理:你的智能助手,真能帮用户“挖出隐藏信息”,还是只会复述FAQ?
- 普通用户:下次你问AI“帮我找所有能治偏头痛的天然草药”,它能不能不漏掉一个?
项目已开放下载,所有数据免费、可商用,支持标准Hugging Face接口。你甚至可以自己写个脚本,让GPT-4、Claude、Gemini、Llama 3轮流来“考试”,看看谁才是真正的“搜索高手”。
项目地址:https://huggingface.co/datasets/google/deepsearchqa#deepsearchqa
这不是一个数据集。这是一场对AI“认知深度”的公开测验。而我们,都是旁观者。