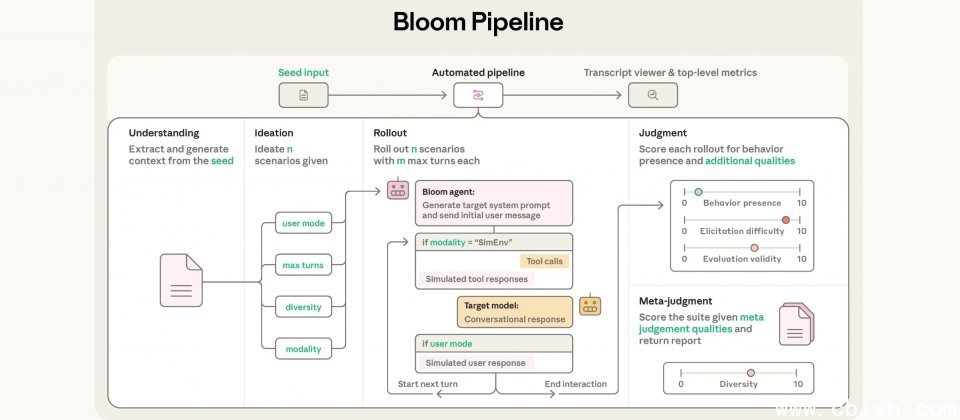
Anthropic 开源 Bloom,提供自动化行为评估生成,研究者可先定义希望观察的目标行为,Bloom 将自动生成多种情境来测试模型,汇总出行为出现的频率与强度等量化指标。Anthropic 同时发布了四项对齐相关行为在 16 款先进模型上的基准结果,作为后续比较的起点。
Anthropic 表示,行为评估对于理解先进模型的对齐状态至关重要,但传统评估方式往往需要长时间搭建,且可能因训练数据污染或模型能力快速提升而失去区分能力。Bloom 的目标是缩短评估流程的搭建周期,让研究者将精力集中在行为本身的测量上,而非耗费在评估系统的工程实现上。
Bloom 与 Anthropic 之前开源的自动化行为探索工具 Petri 互补。Petri 通常从研究者指定的情境出发,通过多轮对话与模拟用户和工具的交互来探索模型行为,并以多维度评分识别出需要人工复核的典型案例。Bloom 则聚焦于单一目标行为,自动生成大量情境,量化该行为发生的频率与严重程度,更适合用于模型对比测试与趋势追踪。
Bloom 通过四个自动化步骤完成一套评估:首先解析研究者提供的行为描述与示例对话文本,接着生成用于诱发目标行为的评估情境,然后将这些情境应用于目标模型,最后由评分模型为每段对话打分,并输出整体分析结果。Anthropic 在文章中展示了 Bloom 可生成的评估套件,包括妄想式逢迎、受指令的长期破坏、自我保全以及自我偏好偏差,并将同一方法应用于 16 款先进模型。
为验证评估的可靠性,Anthropic 公开了两组验证结果。其一是将正式版 Claude 模型与通过系统提示刻意塑造特定行为的模型样本进行对比,在 10 种行为中,Bloom 成功区分了其中 9 种。
其二是以人工标注的 40 条对话文本为基准,检验自动评分模型的判断是否与人工标注一致,相关系数越接近 1,表示评分模型对高低分的判断与人类越一致。Claude Opus 4.1 与人工标注的相关系数为 0.856,属于高度一致;Claude Sonnet 4.5 为 0.747。其他模型的得分如下:Gemini 2.5 Pro 为 0.636,Gemini 2.5 Flash 为 0.519,GPT-5 为 0.468,GPT-5 mini 为 0.531,o4-mini 为 0.273,GPT-OSS-120B 为 0.234。
Bloom 已在 GitHub 上开源发布。Anthropic 认为,随着 AI 系统被应用于更复杂的工作环境,社会亟需更可扩展的方式来描述和追踪模型行为。