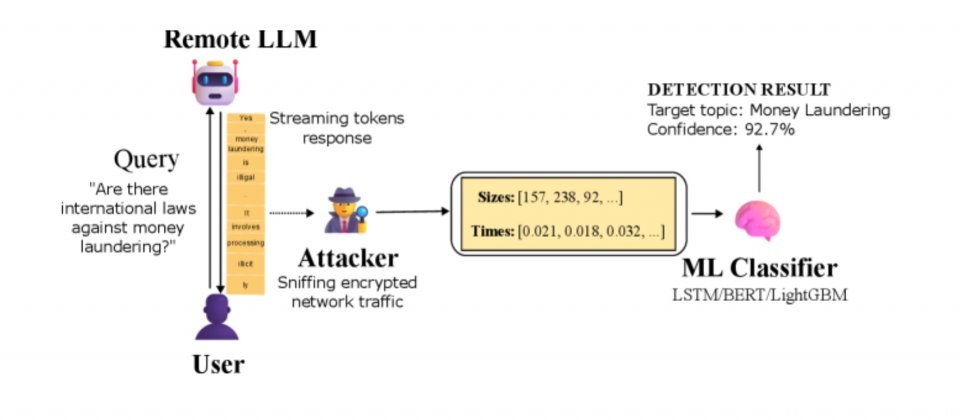
微软发表的Whisper Leak安全研究揭示,即使大型语言模型的对话通过TLS加密,攻击者仍可能仅凭数据包大小与传输时间间隔,推断出用户与聊天机器人的对话主题。也就是说,加密虽能防止内容被窃听,但流量模式本身仍可能成为隐私漏洞。微软指出,已与多家人工智能服务厂商合作修复该风险,包括OpenAI、Mistral与xAI等。
研究人员对大型语言模型的流式响应模式进行了分析。由于模型通常以逐字生成的方式输出Token,用户在输入问题后会实时看到模型生成的文字。研究人员指出,若攻击者能够监控网络流量——无论是通过ISP层级的观测、公共Wi-Fi的窃听,还是同一局域网内的监听——都可在不解密任何内容的情况下,判断出对话主题。
由于大型语言模型在流式响应时是逐个生成Token并传输,每个输出会被转换为一段字节数据并通过数据包发送。即使内容被TLS加密,数据包的长度与发送时间仍保留在网络层可观察的元数据中,这些元数据与模型输出的Token数量、Token长度及分组策略相关。攻击者若收集大量已知主题的样本,便可利用机器学习将数据包长度序列与到达时序作为特征进行训练,学习不同主题对应的流量指纹。当新流量到来时,分类器只需比对这些指纹即可推断主题,无需解密内容。
实验中,研究人员以洗钱的合法性为测试主题,收集多组相关问题,并将其与随机其他对话混合后进行训练。结果显示,即使仅依据加密数据包的大小与时序,机器学习模型仍能准确识别特定主题。多个模型的AUPRC评分超过98;在模拟现实监控场景下,即使在一万次对话中仅有一条为敏感内容,仍能以极高精度识别目标。只要有足够样本与时间,监听者即可建立可靠的分类器。
微软将此类攻击归类为旁道(Side-Channel)分析的一种,不同于以往针对加密算法硬件实现的功耗或电磁分析,Whisper Leak聚焦于应用层的语言模型流量。研究团队指出,这类攻击与2024年学界已披露的Token长度、推理时序、缓存共享等旁道手法属于同一类型,反映出生成式人工智能服务在流式传输阶段的潜在隐私风险。
人工智能服务厂商对此作出回应:OpenAI在流式响应的每个事件中新增了混淆字段,插入随机长度的字符序列,以掩盖单次输出的Token长度信息;微软Azure也采用相同策略。微软表示,该机制已将攻击准确率降至不具备实际威胁的水平。Mistral在Completion API的流式区块中新增了p参数以实现类似效果,xAI也已完成防护部署。