找文件太慢?FindStr 7.03 一键穿透压缩包,全文秒搜不拆包
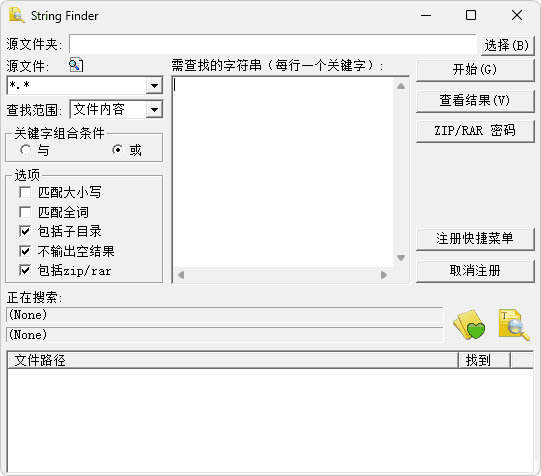
你是不是也遇到过这种情况?硬盘里存了几百GB的小说、源码、技术文档,文件名乱七八糟,想找个“关于线程池优化的Java注释”或“主角叫林晚秋的那章”,翻半天都找不到。Windows自带的搜索?慢得像蜗牛,还占满CPU。手动建索引?太累,记不住,更新又麻烦。
FindStr 7.03,专为这类“资料堆积症”用户打造。它不靠索引,不占资源,直接在你硬盘里“扫雷”——不管文件藏在哪个深层子目录,哪怕它被塞进 ZIP、RAR、EPUB、CBZ、JAR、WAR 里,它都能直接打开,不解压、不提取,一秒定位目标内容。
支持的格式远超你想象
不只是普通的 .zip 和 .rar。只要是常见的压缩封装格式,FindStr 7.03 都能通吃:
- ZIP 家族:.zip、.jar(Java包)、.war(Web应用)、.epub(电子书)、.cbz(漫画压缩包)、.uvz(Ulysses文档)
- RAR 家族:.rar、.cbr(漫画专用)、.cb7(7z漫画包)
你存的电子书、漫画、开源项目、课程资料,全都能直接搜。不用再一个个解压、翻文件、再压缩,省下的是几十个小时的时间。
密码记得住,加密压缩包也能搜
你有没有给重要资料加过密码?普通工具一碰加密压缩包就卡住,FindStr 7.03 不仅能识别加密文件,还能自动记忆密码。你输一次,下次直接跳过。密码支持中文,比如“我的小说密码2024”这种,完全没问题。
注意:密码中不能包含转换成ANSI后变成“”的特殊Unicode字符(如某些emoji或罕见符号),否则无法识别。这个限制是系统底层编码决定的,不是软件问题,我们已尽量优化兼容性。
编码?不用管,它自己会判
你搜的文件可能来自不同系统:Windows记事本保存的ANSI、Linux导出的UTF-8、Mac生成的Unicode……FindStr 7.03 全都认得:
- ANSI:默认支持,中文正常显示
- UTF-8:有BOM(EF BB BF)直接识别;没BOM?它会智能扫描前几KB判断,准确率99%+
- Unicode(UTF-16):必须有FE FF(大端)或FF FE(小端)头标记,识别无误
再也不用担心“怎么搜不到中文”——不是你输错了,是文件编码搞错了。FindStr 7.03 代你处理。
为什么没人用Windows搜索?因为它真的慢
Windows搜索依赖索引服务,启动慢、占用高、更新延迟。你刚存的文件,它可能要等半小时才收录。而FindStr 7.03 是“即点即搜”,像文本编辑器一样轻量,内存占用不到50MB,后台运行毫无压力。尤其适合老电脑、笔记本、服务器环境。
真实用户怎么说?
一位程序员用户反馈:“我存了300多个Java项目,想找一个‘@Scheduled’注解的使用示例,以前要打开10个文件夹,现在输入关键词,3秒出结果,连压缩包里的pom.xml都搜到了。”
一位小说收藏者说:“我有2000多本epub和cbr,想找‘雨夜’‘伞’‘背影’这三个词同时出现的章节,以前得用Calibre一个个打开,现在一键搞定。”
轻量,免费,无广告,无后台
FindStr 7.03 不是试用版,不是会员制,不联网,不上传你的数据。下载即用,绿色单文件(或简单安装包),没有弹窗,没有插件,没有捆绑。你搜的内容,永远只留在你自己的电脑里。
适合谁用?
- 程序员:找代码片段、配置项、日志关键字
- 写作者:翻找旧稿、重复段落、角色名
- 收藏者:管理电子书、漫画、教程文档
- 学生党:整理论文、笔记、参考文献
- 任何被“文件太多、找不到”困扰的人
别再让文件淹没了你的记忆。FindStr 7.03,让搜索回归本质——快、准、不折腾。
