RoboScience发布通用具身大模型Visics,尝试破解机器人泛化难题
6月24日,RoboScience 机器科学正式发布通用具身大模型 Visics,并公开核心技术架构 VLOA。这套架构打通视觉、语言、物体与动作,目标是让机器人摆脱单一任务的重复训练,转向跨本体、跨物体、跨任务的通用操作。
具身智能行业长期依赖“动作复刻”模式。模型死记硬背特定关节的运动轨迹,一旦更换硬件或操作不同物体,能力就会失效。RoboScience 创始人兼 CEO 田野指出,机器人要进入真实世界,必须解决泛化能力弱和长程任务执行困难的问题。
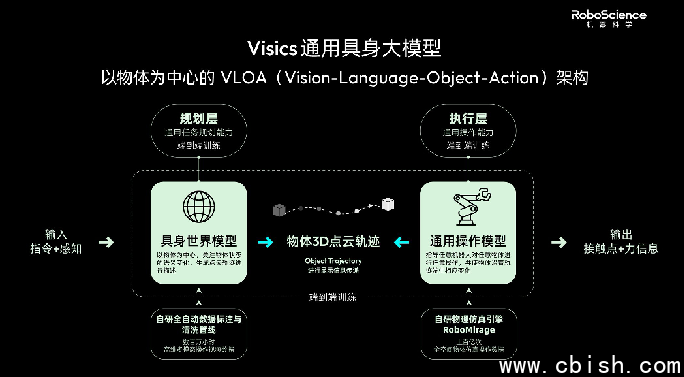
Visics 将“物体3D点云轨迹”作为统一的中间表征标准。模型内部采用双引擎设计。具身世界模型通过海量视频预训练,学习物理世界中物体的运动规律与因果关系。通用操作模型则负责将预判的轨迹直接转化为硬件控制指令。分层解耦后,机器人可以先理解物体运动逻辑,再灵活调用不同躯体完成任务。
数据获取成本高、效率低一直是行业瓶颈。RoboScience 搭建了“仿真+视频”的双数据飞轮。公司自研的高精度仿真引擎 RoboMirage 配合自动化数据标注管线,将单条数据获取成本压至传统方案的百分之一以下。目前数据量以每周数十万小时的速度增长,公司计划到2026年建成1T规模的高质量数据集。

商业落地方面,团队决定从“物体维度”切入。联合创始人汪涛表示,公司优先瞄准商超、物流与康养场景。这些场景对海量SKU和多品类操作的需求更高,团队不会在工业领域直接与现有自动化方案竞争。技术目前已进入零售与物流试点,标准化机器人本体产品计划于年内量产。
从单一任务执行到跨场景泛化,具身智能正从实验室走向产业应用。随着软硬一体化解决方案逐渐成熟,机器人或许能真正具备处理复杂动态环境的底气,在更多生产与服务一线发挥作用。