阿里与人大开源科学生成基础模型 LOGOS
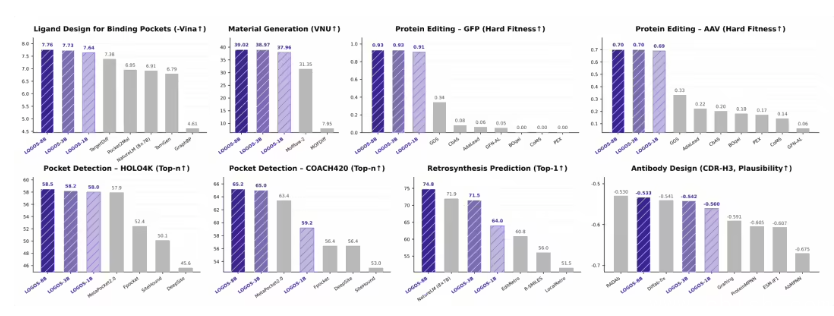
阿里 ATH-Token Foundry 联合中国人民大学高瓴人工智能学院,今日正式开源多领域科学生成基础模型 LOGOS。该模型采用纯序列建模范式,在六项代表性科学任务中,表现已匹配或超过传统的领域专用方法。
LOGOS 展现出较高的参数效率。仅 1B 参数量的 LOGOS-1B 版本,在多个核心任务上跑赢了微软参数量达 8×7B 的 NatureLM 语言模型。
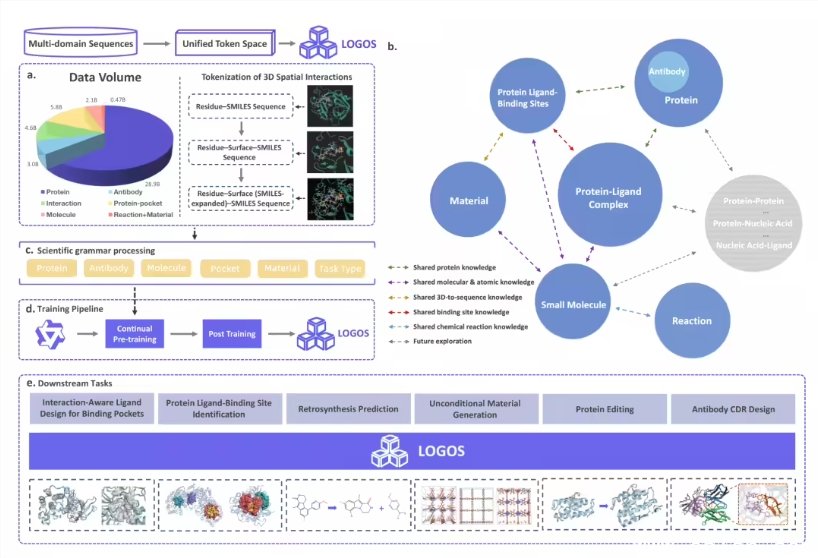
研究团队为 LOGOS 设计了一套统一的科学语法。预训练语料库覆盖生物大分子、化学实体和界面互作等 7 类模态,总量达到 44.87B tokens。通过共享词表,蛋白质和小分子等异构对象被直接编码成统一的离散 Token 序列。这种设计让不同科学对象能在同一个生成空间里被模型自回归理解。模型还引入了一种文字描述法,不需要输入复杂的 3D 坐标,仅靠序列预测就能推演出空间互作规律。
传统科研流程里,切换研究环节通常需要更换模型,落地时还得做大量微调。LOGOS 让预训练数据的序列形式与下游任务的输入输出完全一致。这种对齐方式消除了预训练与实际应用之间的断层,模型不需要复杂的适配层就能直接调用生成能力。目前,阿里已完整开源该模型的权重、推理代码及技术报告。