国际团队发布SWE-Explore基准测试,量化AI编码智能体行级定位短板
包含上海交通大学成员的国际研究团队正式发布评测工具SWE-Explore。该工具将代码搜索与实际修复阶段解耦打分,打破了以往只看最终修复率的单一模式。这组新标准首次量化了当前AI编码智能体在行级精度上的真实短板。
传统SWE-bench等测试只关注端到端结果,智能体在阅读理解阶段的缺陷容易被掩盖。研究人员提取GPT-5.4、Gemini3Pro、Claude Sonnet4.6和Kimi K2.6的成功运行轨迹,用多条独立解路径交汇的共识代码段作为参考值。基于此构建的数据集覆盖十种编程语言、两百零三个开源项目,包含八百四十八个缺陷任务。
实测数据显示出明显的断层现象。Claude Code、OpenHands 等通用编码智能体在文件级定位上表现稳定,但下钻到具体代码行时,核心区域覆盖率直接跌至 14% 到 19%。
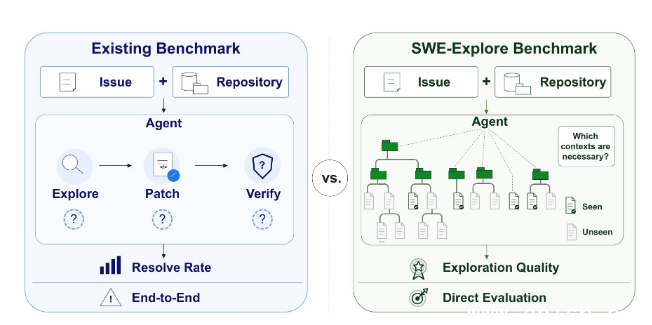
消融实验进一步验证了最小上下文阈值效应。当关键区域的可见比例低于 50% 时,模型修复基本无法完成。跨过 50% 至 75% 的临界点之后,修复成功率才出现明显反弹。智能体的真正瓶颈不在于补丁编写,在于对关键上下文的精准过滤与捕捉。
目前行业内多数项目经理已经拒绝采纳半数的自动化修复方案。SWE-Explore 提出的少过滤、多阅读技术路线,正在为 CoSIL 等下一代代码定位系统的架构优化指明方向。自动化工具的开发重心也会随之从暴力生成转向精准检索。